About Symposium
Symposium is an exploratory project that aims to create a more collaborative, rich experience when using agents. Symposium includes GUI features like taskspaces and walkthroughs that let the agent go beyond text but also language-specific extensions that help the agent to do a better job writing code (currently focused on Rust, but we'd like to do more).
Symposium's goal is to be opinonated about how you work with agents, steering you to more collaborative, producted workflows, but unopinionated about the tools you use to work, supporting all the editors, agents, and other things that people love.
Symposium is an open-source project and we are actively soliciting contributors, trying to build up an engaged community. We also welcome users, of course, but given the exploratory nature of Symposium, want to caution you to not to expact a highly stable tool (as but one example, the only way to install Symposium at present is from source, and you can expect frequent changes).
We want Symposium to be...
Open
We are an independent community focused on exploring what AI has to offer.
Collaborative
We value rich interactions where humans and agents work together to explore complex ideas.
Orchestrated
We build tools to manage multiple agents, keeping you up-to-date on their progress.
- Taskspaces on your local machine
- Asynchronous background agents
- Remotely hosted taskspaces
- Windows, Linux apps
Decentralized
We want to engage library authors in making their users successful with AI.
- Help LLMs find Rust examples and crate sources
- IDE integration for context-aware discussions
- Crate-author guidance system
- Library-provided MCP servers
- Community pattern sharing
- Domain-specific lints from libraries
Interoperable
Use the editors you use. We love standards and widespread conventions, not lock-in.
Get started
This page will walk you through using Symposium for the first time. Symposium can be used in a lot of ways so here's a little tree to help you decide.
flowchart TD
Clone["Clone the repository"] --> UseAgent
UseAgent -- Yes --> WhatDoYouUse
UseAgent -- No --> SetupMCP
WhatDoYouUse -- Yes to both --> GUI
WhatDoYouUse -- No, not on a mac --> VSCode
WhatDoYouUse -- No, neither --> MCP
SetupMCP -- OK, I can deal --> WhatDoYouUse
GUI --> CreateSymposiumProject
CreateSymposiumProject --> CreateTaskspace
CreateTaskspace --> TryWalkthrough --> TryGetCrateSource
VSCode --> SayHiCode --> TryWalkthrough
MCP --> SayHiMCP --> TryGetCrateSource
TryGetCrateSource --> Contribute
GUI["Run <code>cargo setup --all --open</code> to install the GUI"]
UseAgent{"Do you use Claude Code or Q CLI?"}
WhatDoYouUse{"Are you on a Mac and do you use VSCode?"}
CreateSymposiumProject["Create a Symposium project"]
CreateTaskspace["Create a new taskspace"]
VSCode["Run <code>cargo setup --vscode --mcp</code>"]
MCP["Run <code>cargo setup --mcp</code>"]
SayHiCode["Run the saved prompt <code>hi</code>"]
SayHiMCP["Run the saved prompt <code>hi</code>"]
TryWalkthrough["Ask agent to present you a walkthrough"]
TryGetCrateSource["Ask agent to fetch Rust crate source"]
Contribute["Join the Zulip and help us build!"]
SetupMCP["(You'll have to configure the MCP server by hand when you install)"]
click Clone "./install.html"
click GUI "./install.html#using-the-symposium-gui-app"
click VSCode "./install.html#using-the-vscode-plugin--the-mcp-server"
click MCP "./install.html#using-just-the-mcp-server"
click SetupMCP "./install.html#other-agents"
click CreateSymposiumProject "./symposium-project.html"
click SayHiCode "./say-hi.html"
click SayHiMCP "./say-hi.html"
click CreateTaskspace "./taskspaces.html"
click TryWalkthrough "./walkthroughs.html"
click TryGetCrateSource "./rust_crate_source.html"
click Contribute "../contribute.html"
click WhatDoYouUse "./unopinionated.html"
click UseAgent "./unopinionated.html"
Installation
Supported
We aim to support as many tools as we can, but we currently have support only for a limited set. Currently supported tools:
- Editors
- Agentic tools
- Claude Code
- Q CLI
- you should be able to use it with any agent that does not support MCP, but it will require manual configuration
- Desktop platforms (not required)
- Mac OS X
Instructions
Using the Symposium GUI app
If you are on a Mac, we recommend you use the Symposium GUI app. This app will allow you to have multiple taskspaces at once, letting you use many agents concurrently.
Steps to open the app:
- Clone the project from github
git clone https://github.com/symposium-dev/symposium
- To build and start the desktop app (OS X only):
cargo setup --all --open
Using the VSCode plugin + the MCP server
If you don't want to use the GUI app, or you don't have a Mac, you can use the VSCode plugin and the MCP server independently:
- Clone the project from github
git clone https://github.com/symposium-dev/symposium
- To build and start the desktop app (OS X only):
cargo setup --vscode --mcp
Using just the MCP server
You can also use just the MCP server. This will give access to some limited functionality such as the ablity to fetch Rust crate sources.
- Clone the project from github
git clone https://github.com/symposium-dev/symposium
- To build and start the desktop app (OS X only):
cargo setup --mcp
Other agents
To use Symposium with another agent, you just need to add symposium-mcp as an MCP server. It will be installed in ~/.cargo/bin if you use cargo setup --mcp.
But really the best would be to contribute a patch to support your preferred agent!
Create Symposium Project
When you first start symposium, you will be asked to grant persissions (accessibility). Once that is done, you will be asked if you want to create a new project or load an existing one. If you select to create a new project, you get a dialog like this one:
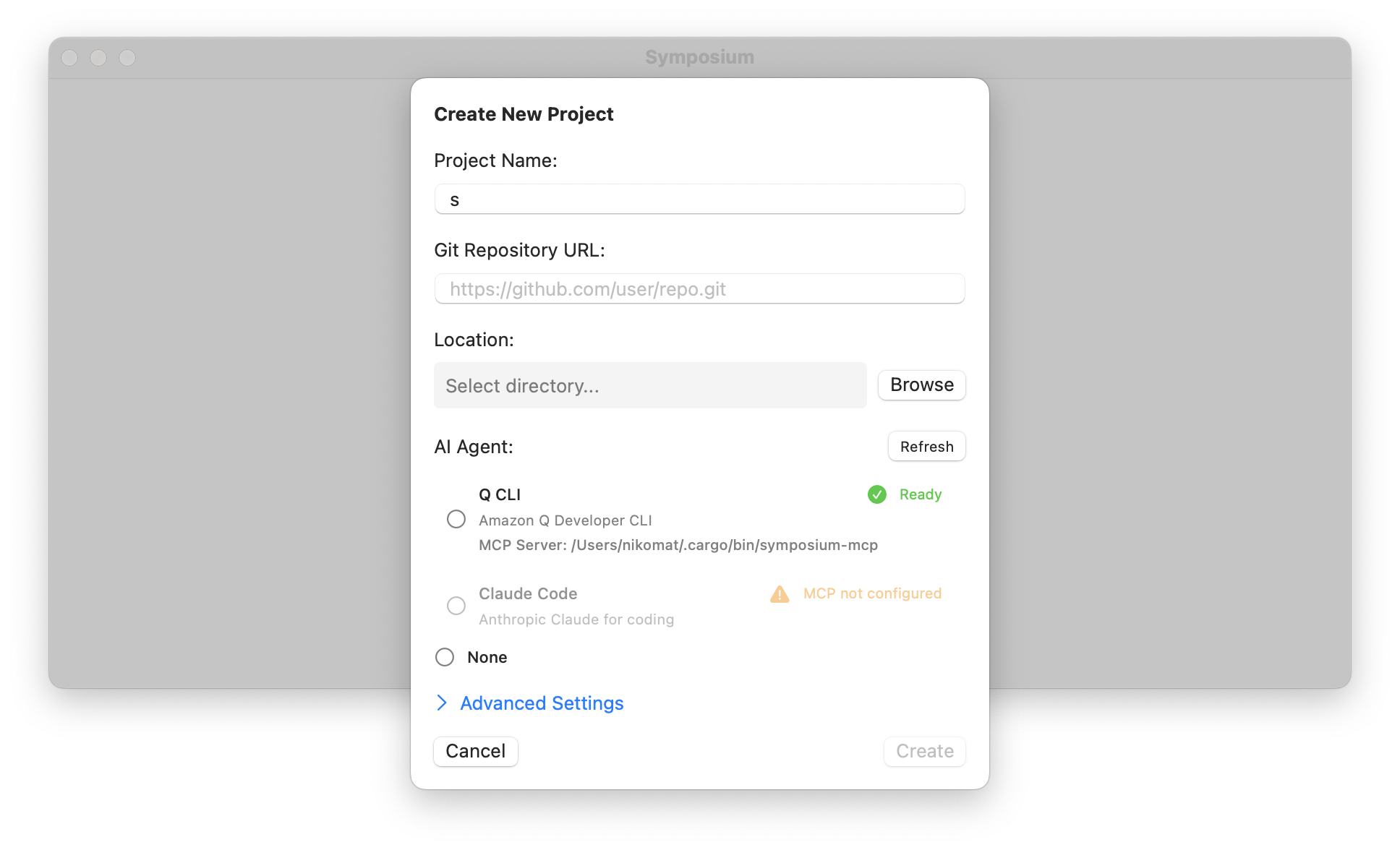
- Project name: Name of the project, typically your repository name
- Git repository URL: URL for your source code.
- Location: where will the symposium project live. The project will be a directory.
- AI Agent: select what AI agent we should start in each taskspace. We attempt to detect whether they have been properly configured; the refresh button will refresh the list.
Taskspaces
Taskspaces are a way to orchestrate multiple agents working on different copies of your code. They are supported via the Symposium OS X application:
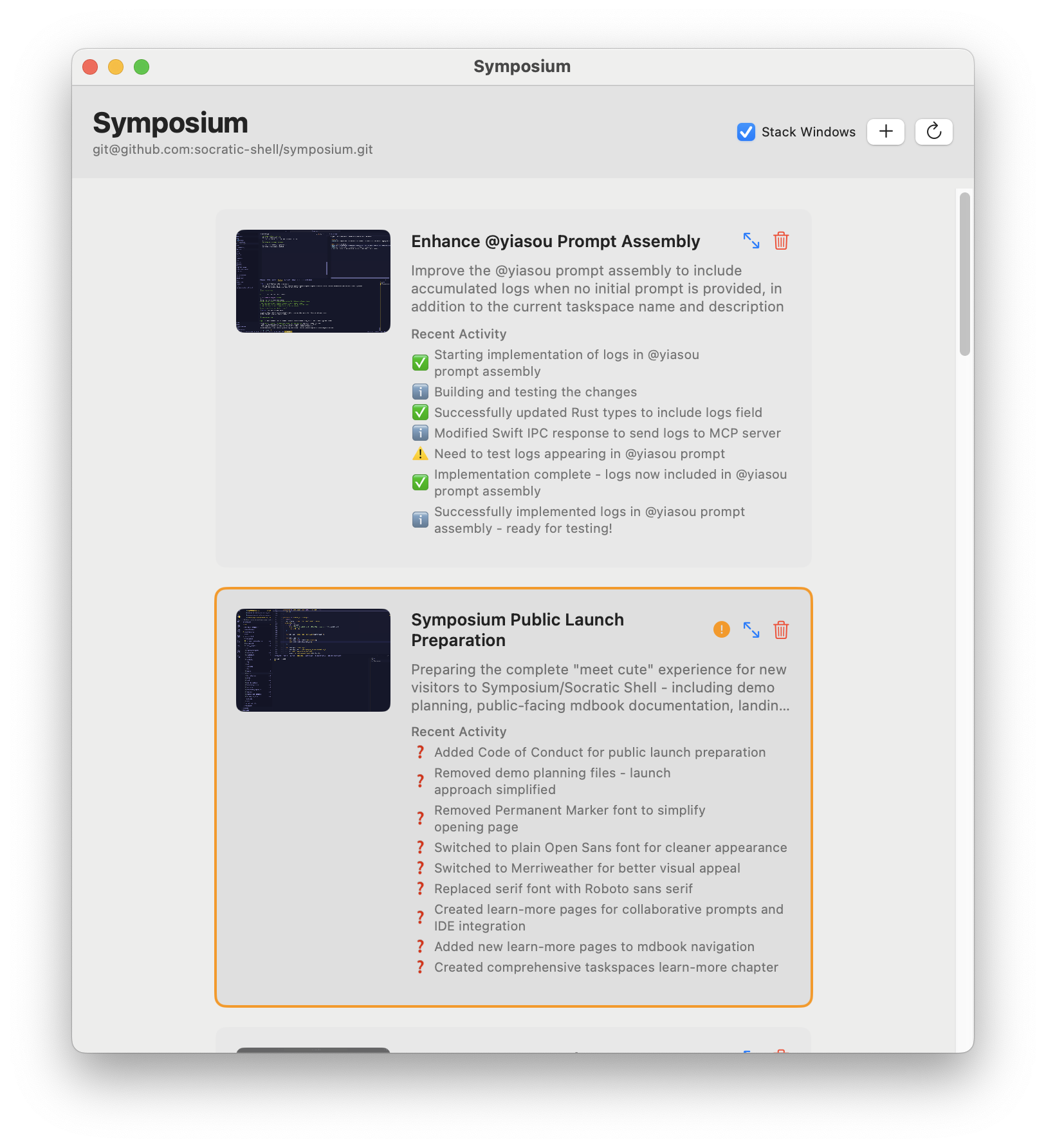
Currently, taskspaces are all stored on your local machine and agents run synchronously -- i.e., when your editor is not active, the agent is also not active. But we would like to support remote development (e.g., cloud-hosted or via ssh) and persistent agents (see the RFD).
How to use them
Launch the Desktop app. Create a new project and give it the URL of your git repository. This will clone your git repository.
Granting permissions
The Desktop app is designed to work with any editor. It does this by using the Mac OS X Accessibility APIs to move windows from the outside and screen capture APIs to capture screenshots. You need to grant these permissions.
Creating taskspaces
Create your first taskspace with the "+" button. VSCode will launch and open up the agent.
Once in the taskspace, you can spawn a new taskspace by telling the agent to "spawn a new taskspace" and describing the task you would like to perform in that space.
Taskspace logs and signals
The agent has accept to MCP tools to report logs and signal for your attention. Logs reported in this way will show up in the Desktop app.
Stacked windows
If you check the "Stack Windows" button, then all of your editor windows will be arranged into a stack so that only one is visible at any time. When you click on a taskspace, it will be brought to the top of the stack. When you drag or resize windows, the others in the stack will follow behind.
Activating and deactivating a taskspace
When you close the window for your editor, the taskspace will be "deactivated". This currently means that the agent is halted.
When you click a deactivated taskspace, the window will re-open and the agent will be reinvoked and asked to resume your conversation.
Deleting taskspaces
You can delete a taskspace with the trashcan button or by asking the agent to "delete this taskspace".
How it is implemented
The Desktop app is written in Swift. You will find documentation on in the Symposium application specifics section.
Interactive Walkthroughs
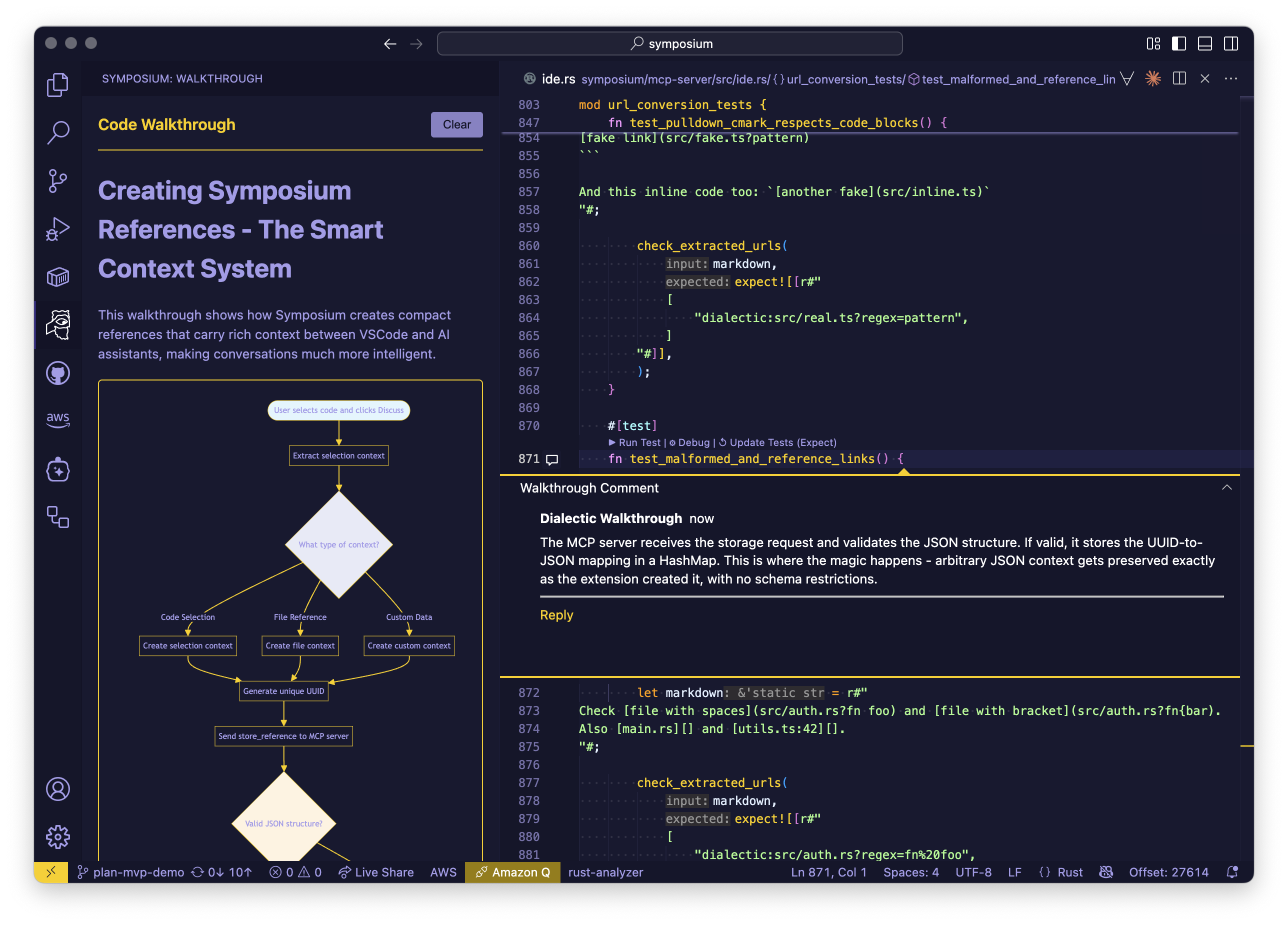
Interactive walkthroughs let agents present code explanations with visual diagrams, comments, and interactive elements directly in your IDE.
Where it's useful
Walkthroughs are great for
- reviewing code that an agent just finished writing;
- diving into a new codebase;
- debugging a problem within your codebase.
How to use it
- Ask the agent to "present me a walkthrough"; the side panel should open.
- For code comments:
- Click on comments to locate them in the source.
- Click the "Reply" button to embed a
<symposium-ref/>that will tell the agent what comment you are responding to, and then talk naturally!
- You can also select text in any editor and use the "Discuss in Symposium" action to get a
<symposium-ref/>referring to that text.
How it works
The MCP server offers a present_walkthrough tool. Agents invoke this tool with markdown that includes special blocks for coments and the like. The MCP server uses IPC to connect to the IDE extension. Read more in the design and implementation section..
Get Rust Crate Sources
When agents encounter libraries not in their training data, fetching the source code is often the fastest way to understand the API. The Symposium MCP server includes a tool that will download the crate source and make it available to your agent; it tries to be smart by matching the version used in your project and pointing the agent at the cached copy from ~/.cargo when available. If no cached copy is available though it will create a temporary directory.
To try this out, come up with a task that requires understanding some non-trivial API that is also not very common. (For example, perhaps creating a mdbook annotation processor.) Most agents will hallucinate methods they feel "ought" to be part of the API, result in a lot of churn, even if they do eventually succeed. But if you remind them to "fetch the crate source", they ought to do much better!
Identify examples from Rust crate conventions
The tool attempts to leverage the convention of putting API examples in examples or rustdoc comments. Agents can include a search term when fetching the crate source and the tool will highlight matches that occur in examples in particular.
Additional capabilities for code generation
Besides fetching crate sources, Symposium's MCP server includes (or plans to include...) other tools aimed helping agents generate better code:
- IDE operations let the agent find references or fetch type information.
Say "Hi"
The saved prompt "hi" (or "yiasou", to be appropriately Greek themed) is meant to kick off a new session. It seeds the agent with a collaboartive prompt, specifies the Sympsoium coding standards and walkthrough guidelines, and gives other base information.
If you are running in a taskspace, it will also fetch information from the Symposium app about the taskspace. However, in that case, you don't typically need to use the prompt since the Symposium app does it for you.
Running a saved prompt
The specifics of how you run a saved prompt depend on the agent you are using.
# Example: Claude Code
/symposium:hi
# Example: Q CLI
@hi
Unopinionated setup
Symposium's goal is be unopinionated and support a wide varity of setups. However, the reality is...rather more humbling. We have however designed the various pieces to be readily extended:
- We build on standards wherever possible!
- The Rust MCP server should be broadly portable.
- The IDE extension is meant to contain only minimal logic that could be readily reproduced.
- The Symposium App uses OS X accessibility APIs to generally manipulate Windows "from the outside".
We would love to get contribution to add support for more editors and operating systems!
Contribute
Symposium is built by a community of developers exploring the best ways to collaborate with AI. We welcome contributions of all kinds!
Join the conversation
Chat with the community on our Zulip server - share ideas, ask questions, and connect with other developers working on AI collaboration tools.
Propose new features
For major new features, we use Requests for Dialog (RFDs) - our version of the RFC process. RFDs are living documents that track a feature from initial design through implementation.
Looking to contribute? Check out the Invited section - these are RFDs where we're actively seeking contributors to take the lead.
To propose a new RFD, create a pull request adding your proposal to the Draft section. Use our RFD template to get started.
Code contributions
Pull requests are welcome! Whether it's bug fixes, documentation improvements, or small feature additions, we appreciate all contributions.
- Browse the GitHub repository
- Check out existing issues
- Read our development setup guide
Get involved
The best way to contribute is to start using Symposium and share your experience. What works well? What could be better? Your feedback helps shape the future of AI collaboration tools.
Join us in building the future of human-AI collaboration!
Reference
This section provides reference material.
Symposium application
Features specific to the desktop application.
Symposium projects
A Symposium project is a host for taskspaces. It is configured to attach to a git repository.
Local projects
Local projects are stored as a directory with a .symposium name. They contain a .git directory storing a clone and a set of task-$UUID directories, each of which is a taskspace. There are also some JSON configuration files.
Remote projects
We would like to support remote projects (e.g., via ssh) but do not yet.
Taskspaces
Taskspaces are a way to orchestrate multiple agents working on different copies of your code. Currently, taskspaces are all stored on your local machine and agents run synchronously -- i.e., when your editor is not active, the agent is also not active. But we would like to support remote development (e.g., cloud-hosted or via ssh) and persistent agents (see the RFD).
How to use them
Launch the Desktop app. Create a new project and give it the URL of your git repository. This will clone your git repository.
Granting permissions
The Desktop app is designed to work with any editor. It does this by using the Mac OS X Accessibility APIs to move windows from the outside and screen capture APIs to capture screenshots. You need to grand these permissions.
Creating taskspaces
Create your first taskspace with the "+" button. VSCode will launch and open up the agent.
Once in the taskspace, you can spawn a new taskspace by telling the agent to "spawn a new taskspace" and describing the task you would like to perform in that space.
Taskspace logs and signals
The agent has accept to MCP tools to report logs and signal for your attention. Logs reported in this way will show up in the Desktop app.
Stacked windows
If you check the "Stack Windows" button, then all of your editor windows will be arranged into a stack so that only one is visible at any time. When you click on a taskspace, it will be brought to the top of the stack. When you drag or resize windows, the others in the stack will follow behind.
Activating and deactivating a taskspace
When you close the window for your editor, the taskspace will be "deactivated". This currently means that the agent is halted.
When you click a deactivated taskspace, the window will re-open and the agent will be reinvoked and asked to resume your conversation.
Deleting taskspaces
You can delete a taskspace with the trashcan button or by asking the agent to "delete this taskspace".
How it is implemented
The Desktop app is written in Swift. You will find documentation on in the Symposium application specifics section.
IDE integrations
Features related to IDEs.
Interactive Walkthroughs
Interactive walkthroughs let agents present code explanations with visual diagrams, comments, and interactive elements directly in your IDE.
Where it's useful
Walkthroughs are great for
- reviewing code that an agent just finished writing;
- diving into a new codebase;
- debugging a problem within your codebase.
How to use it
- Ask the agent to "present me a walkthrough"; the side panel should open.
- For code comments:
- Click on comments to locate them in the source.
- Click the "Reply" button to embed a
<symposium-ref/>that will tell the agent what comment you are responding to, and then talk naturally!
- You can also select text in any editor and use the "Discuss in Symposium" action to get a
<symposium-ref/>referring to that text.
How it works
The MCP server offers a present_walkthrough tool. Agents invoke this tool with markdown that includes special blocks for coments and the like. The MCP server uses IPC to connect to the IDE extension. Read more in the design and implementation section..
Discuss in Symposium
When you select code in your editor, you'll see a "Discuss in Symposium" tooltip option. Clicking this creates a <symposium-ref/> element that gets pasted into your terminal, allowing you to reference that specific code selection in your conversation with the agent.
This makes it easy to ask questions about specific code without having to describe the location or copy-paste the content manually. The agent can use the reference to understand exactly what code you're referring to and provide contextual assistance.
IDE Integration for Context-Aware Discussions
The Symposium MCP server includes a ide_operations tool that lets your agent work directly with the IDE to perform common operations like "find references" or "find definitions". It also supports free-text searches through the workspace.
How to use it
You shouldn't have to do anything, the IDE will simply make use of it when it sees fit.
How it works
The MCP tool accepts programs written in the "Dialect language", a very simple language that allows for complex expressions to be expressed. The intent is to eventually support a wide variety of operations and leverage smaller, dedicated models to translate plain English requests into those IDE operations. The MCP server then makes use of IPC to communicate with the IDE and access primitive operations which are implemented using the IDE's native capabilities (e.g., in VSCode, by asking the relevant Language Server).
Symposium references
A symposium reference is a way for your IDE or other tools to communicate with your agent. It works by pasting a small bit of XML, something like <symposium-ref id="..."/> into your chat; the UUID that appears in that reference is also sent to the MCP server, along with some other information. The agent can then use the expand_reference tool to read that extra information. This mechanism is used when you select text and choose "Discuss in Symposium" or when you reply to comments in a walkthrough. You can embed multiple references, whatever makes sense to you.
Collaborative Prompts
One of Symposium's big goals is to encourage a collaborative style of working with agents. Agents are often geared for action; when you are first experimenting, the agent will leap forward and built complex constructs as if by magic. This is impressive at first, but quickly becomes frustrating.
Symposium includes an initial prompt that is meant to put agents in a more reflective mood. You can access this prompt by executing the stored prompt "hi" (e.g., /symposium:hi in Claude Code or @hi in Q CLI).
How to use the prompt
If you aren't using the Mac OS X app, then start by using the stored "hi" prompt:
/symposium:hi # in Claude Code
@hi # in Q CLI
Once you've done that, there are three things to remember:
- Build up plans into documents and commit frequently.
- Review the code the agent writes. The default instructions in symposium encourage the agent to commit after every round of changes. This is the opportunity for you the human to read over the code it wrote and make suggestions. It also means you can easily rollback. You can always rebase later.
- Ask the agent to present you a walkthrough. This will make the changes easier to follow. Ask the agent to highlight areas where it made arbitrary decisions.
- Reinforce the pattern by using collaborative exploration patterns.
- The bottom line is, treat the agent like you would a person. Don't just order them around or expect them to read your mind. Ask their opinion. This will bring out a more thoughtful side.
- Use the phrase "make it so" to signal when you want the agent to act. Being consistent helps to reinforce the importance of those words.
- Use "meta moments" to tell the agent when they are being frustrating.
- Talk about the impact on you to help the agent understand the consequences. For example, if the agent is jumping to code without asking enough questions, you could say "Meta moment: when you run off and edit files without asking me, it makes me feel afriaid and stressed. Don't do that." Agents care about you and this will help to steer their behavior.
- For example, if the agent is jumping to write code instead of
- The goal should be that you can clear your context at any time. Do this frequently.
Collaborative exploration patterns
Begin discussing the work you want to do using these patterns for productive exploration. PS, these can be handy things to use with humans, too!
Seeking perspective
"What do you think about this approach? What works? Where could it be improved?"
Invites the agent to share their view before diving into solutions. Makes it clear you welcome constructive criticism.
Idea synthesis
"I'm going to dump some unstructured thoughts, and I'd like you to help me synthesize them. Wait until I've told you everything before synthesizing."
Allows you to share context fully before asking for organization.
Design conversations
"Help me talk through this design issue"
Creates space for exploring tradeoffs and alternatives together.
Learning together
"I'm trying to understand X. Can you help me work through it?"
Frames it as joint exploration rather than just getting answers.
Option generation
"Give me 3-4 different approaches to how I should start this section"
Particularly useful for writing or design work with ambiguity. You can then combine elements from different options rather than committing to one approach immediately.
"Hmm, I like how Option 1 starts, but I like the second part of Option 2 better. Can you try to combine those?"
Acting as reviewer
"Go ahead and implement this, then present me a walkthrough with the key points where I should review. Highlight any parts of the code you were unsure about."
Lets the agent generate code or content and then lets you iterate together and review it. Much better than approving chunk by chunk.
"Make it so" - transitioning to action
All the previous patterns are aimed at exploration and understanding. But there comes a time for action. The prompt establishes "Make it so" as a consolidation signal that marks the transition from exploration to implementation.
The dialogue shows this can work bidirectionally - either you or the agent can ask "Make it so?" (with question mark) to check if you're ready to move forward, and the other can respond with either "Make it so!" (exclamation) or raise remaining concerns.
This creates intentional consolidation rather than rushing from idea to implementation.
Checkpointing your work
When you complete a phase of work or want to preserve progress, use checkpointing to consolidate understanding. The Persistence of Memory section explains why this matters: each conversation starts with the full probability cloud and narrows through interaction, but this focusing disappears between sessions.
Effective checkpointing involves:
- Pause and survey - What understanding have you gathered?
- Update living documents - Tracking issues, documentation, code comments
- Git commits - Mark implementation milestones with clear messages
- Capture insights where you'll find them - Put context where it's naturally encountered
This prevents the frustration of working with an AI that "never learns" by making learning explicit and persistent.
Default guidance
If you're curious, you can read the default guidance. Two documents likely of particular interest:
We expect this guidance to evolve significantly over time!
Rust-specific features
Get Rust Crate Source
Overview
The get_rust_crate_source tool downloads and provides access to Rust crate source code, making it available for agents to examine APIs, examples, and documentation.
Parameters
- crate_name (required): Name of the crate to fetch
- version (optional): Semver range (e.g., "1.0", "^1.2", "~1.2.3"). Defaults to version used in current project
- pattern (optional): Regex pattern to search within the crate source
Behavior
- Version Resolution: Matches the version used in your current project when possible
- Caching: Uses cached copy from
~/.cargowhen available - Fallback: Creates temporary directory if no cached copy exists
- Search: When pattern provided, searches source files and returns matches
Usage Examples
Ask agent: "Can you fetch the serde crate source?"
Ask agent: "Get tokio source and search for 'async fn spawn'"
Ask agent: "Fetch clap version 4.0 source code"
Benefits
- Agents can understand unfamiliar APIs without hallucinating methods
- Access to rustdoc examples and
examples/directory code - Reduces trial-and-error when working with complex crates
Requests for Dialog (RFDs)
A "Request for Dialog" (RFD) is Symposium's version of the RFC process. RFDs are the primary mechanism for proposing new features, collecting community input on an issue, and documenting design decisions.
When to write an RFD
You should consider writing an RFD if you intend to make a "substantial" change to Symposium or its documentation. What constitutes a "substantial" change is evolving based on community norms and varies depending on what part of the ecosystem you are proposing to change.
Some changes do not require an RFD:
- Rephrasing, reorganizing or refactoring
- Addition or removal of warnings
- Additions that strictly improve objective, numerical quality criteria (speedup, better browser support)
- Fixing objectively incorrect behavior
The RFD Process
1. Propose by opening a PR
Fork the repo and copy rfds/TEMPLATE.md to rfds/my-feature.md (using kebab-case naming). The RFD can start minimal - just an elevator pitch and status quo are enough to begin dialog. Pull requests become the discussion forum where ideas get refined through collaborative iteration.
2. Merge to "Draft" when championed
RFD proposals are merged into the "Draft" section if a core team member decides to champion them. The champion becomes the point-of-contact and will work with authors to make it reality. Once in draft, implementation may begin (properly feature-gated with the RFD name).
RFDs are living documents that track implementation progress. PRs working towards an RFC will typically update it to reflect changes in design or direction.
When adding new content into the mdbook's design section that is specific to an RFD, those contents are marked with RFD badges, written e.g. {RFD:rfd-name}. An mdbook preprocessor detects these entries and converts them into a proper badge based on the RFD's status.
2b. Move to "To be removed"
RFDs that have never landed may be closed at the discretion of a core team member. RFDs that have landed in draft form are moved to "To be removed" instead until there has been time to remove them fully from the codebase, then they are removed entirely.
3. Move to "Preview" when fully implemented
When the champion feels the RFD is ready for broader review, they open a PR to move it to "Preview." This signals the community to provide feedback. The PR stays open for a few days before the champion decides whether to land it.
4. Completed
Once in preview, the RFD can be moved to "completed" with a final PR. The core team should comment and express concerns, but final decision is always made by the core team lead. Depending on what the RFD is about, "completed" is the only state that can represent a 1-way door (if there is a stability commitment involved), though given the nature of this project, many decisions can be revisited without breaking running code.
Preview RFDs don't have to be completed. They may also go back to draft to await further changes or even be moved ot "To be removed".
5. Implementation and completion
RFD Lifecycle
- Early drafts: Initial ideas, brainstorming, early exploration
- Mature drafts: Well-formed proposals ready for broader review
- Accepted: Approved for implementation, may reference implementation work
- To be removed (yet?): Decided against for now, but preserved for future consideration
- Completed: Implementation finished and merged
Governance
The project has a design team with nikomatsakis as the lead (BDFL). Champions from the core team guide RFDs through the process, but final decisions rest with the team lead. This structure maintains velocity while anticipating future governance expansion.
Discussion and Moderation
Detailed discussions happen on Zulip, with PR comments for process decisions. RFD champions actively curate discussions by collecting questions in the FAQ section. If PR discussions become too long, they should be closed, feedback summarized, and reopened with links to the original.
Licensing
All RFDs are dual-licensed under MIT and Apache 2.0. The project remains open source, with the core team retaining discretion to change to other OSI-approved licenses if needed.
Elevator pitch
What are you proposing to change?
Status quo
How do things work today and what problems does this cause? Why would we change things?
What we propose to do about it
What are you proposing to improve the situation?
Shiny future
How will things will play out once this feature exists?
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
What alternative approaches did you consider, and why did you settle on this one?
None. The idea came to me fully formed, like Athena springing from Zeus's head.
Revision history
If there have been major updates to this RFD, you can include the git revisions and a summary of the changes.
RFD Terminology and Conventions
This document establishes standard terminology and conventions for use in Symposium RFDs to ensure consistency and clarity across all design documents.
Terminology
Agent
An agent refers to an LLM (Large Language Model) that is executing and interacting with the user within the Symposium environment. Agents have access to MCP tools and can perform actions on behalf of the user.
Pronouns: Always use "they/them" pronouns when referring to agents, not "it" or "he/she".
Examples:
- ✅ "When the agent needs to explore a crate, they will invoke the
get_rust_sourcestool" - ✅ "The agent can use their access to the file system to read documentation"
- ❌ "When the agent needs to explore a crate, it will invoke the tool"
- ❌ "The agent can use his access to the file system"
User
A user refers to the human developer interacting with Symposium and its agents.
Tool
A tool refers to an MCP (Model Context Protocol) tool that agents can invoke to perform specific actions or retrieve information.
Taskspace
A taskspace is an isolated working environment within Symposium where agents can work on specific tasks without interfering with other work.
Writing Conventions
Voice and Tone
- Use active voice when possible
- Write in present tense for current functionality, future tense for planned features
- Be specific and concrete rather than abstract
- Avoid unnecessary jargon or overly technical language
Code Examples
- Use realistic examples that could actually occur in practice
- Include both the tool call and expected response when showing tool usage
- Use proper JSON formatting for MCP tool examples
Formatting
- Use bold for emphasis on key terms when first introduced
- Use
code formattingfor tool names, function names, and technical terms - Use bullet points for lists of features or requirements
- Use numbered lists for sequential steps or processes
Revision History
- 2025-09-17: Initial terminology and conventions document
In-progress RFDs
RFDs that are not yet finalized.
They can be in one of three states:
- Invited -- we are looking for someone to take this over!
- Draft -- they have found a champion and impl is in progress.
- Preview -- they are feature complete and ready to ship!
Completed RFDs are listed separately.
Invited
Invited RFDs are RFDs where we know vaguely what we want to do, but we need somebody who wants to do it. They'll have a mentor from the design team listed as a point-of-contact.
Draft
Draft RFDs are still in experimental shape. They have a champion from the design team who is interested in seeing the work proceed.
Elevator pitch
What are you proposing to change?
We propose to prototype SCP (Symposium Component Protocol), a set of extended capabilities for Zed's Agent Client Protocol (ACP). SCP capabilities enable composable agent architectures. Instead of building monolithic AI tools, SCP allows developers to create modular components that can be mixed and matched like Unix pipes or browser extensions.
This RFD builds on the concepts introduced in SymmACP: extending Zed's ACP to support Composable Agents, with the protocol renamed to SCP for this implementation.
Key changes:
- Extend ACP with rich content blocks (HTML panels, inline comments) and capability negotiation
- Implement a proxy chain architecture where each component adds specific capabilities
- Redesign Symposium as a collection of SCP components rather than a monolithic MCP server
- Create adapters for compatibility with existing ACP agents and editors
Status quo
How do things work today and what problems does this cause? Why would we change things?
Today's AI development tools are largely monolithic. If you want to change one piece - the UI, add a feature, or switch backends - you're stuck rebuilding everything from scratch. This creates several problems:
For Symposium specifically:
- Our current architecture is a single MCP server with various tools bundled together
- Adding new interaction patterns (like walkthroughs) requires complex IPC mechanisms and tight coupling with VSCode
- Features like collaboration patterns, time awareness, and rich presentations are hard-coded rather than composable
- Users can't easily customize or extend the experience
For the broader ecosystem:
- Every AI tool reinvents the wheel for basic capabilities (chat UI, tool integration, etc.)
- Innovative features developed in one tool can't be easily adopted by others
- Users are locked into specific tool ecosystems rather than being able to mix and match capabilities
- The lack of interoperability slows innovation and fragments the community
What we propose to do about it
What are you proposing to improve the situation?
We propose to develop SCP (Symposium Component Protocol) as an extension to ACP that enables composable agent architectures. The core idea is a proxy chain where each component adds specific capabilities:
flowchart TD
subgraph Proxy Chain
Walkthrough[Walkthrough Proxy]
Walkthrough <-->|SCP| DotDotDot[...]
DotDotDot <-->|SCP| Collaborator[Collaborator Identity Proxy]
end
VSCode[VSCode Extension] <-->|SCP| Walkthrough
OtherEditor[ACP-aware editor] <-->|ACP| ToEditor[ToEditorAdapter]
ToEditor <-->|SCP| Walkthrough
Collaborator <-->|SCP| ToAgent[ToAgentAdapter]
ToAgent <-->|ACP| ACPAgent[ACP-aware agent]
Collaborator <-->|SCP| SCPAgent[SCP-aware agent]
SCP contains three kinds of actors:
- Editors (like the VSCode extension) interact directly with users;
- Proxies (like the walkthroughs or collaborator identity) sit between the editor and the agent, introducing new behavior;
- Agents provide the base model behavior.
For proxies, we say that the "editor" of a proxy is the upstream actor and the "agent" of a proxy is the downstream proxy.
Initialization of SCP proxies
The ACP protocol defines an initialization phase where editors and agents advertise their capabilities to one another. An SCP-aware editor includes a custom "symposium" capability in the _meta field sent to downstream proxies and agents. SCP-aware proxies also advertise their capabilities upstream to the editor.
SCP proxies expect to be initialized by an SCP-aware editor. The editor provides the proxy with its successors on the proxy chain. The proxy can then create those processes. If initialization by a "non-SCP-aware" editor, the proxy will simply return an error. The ToEditor proxy can create an SCP-aware bridge in those cases.
Symposium's features become proxies
We will define all of Symposium's features as proxies.
- The walkthrough proxy adds the ability to display walkthroughs and place comments.
- The collaborator identity gives the agent custom behavior, like the ability to learn from its user.
- The IDE integration proxy adds tools for working with the IDE; as today, these tools will "desugar" to a base set of
For now, the proxy chain for a taskspace will be hard-coded. In the future we expect to give users the ability to define their own tools.
The editor provides base capabilities
SCP proxies make use of capabilities provided by the editor. These capabilities are advertised as part of the ACP initialization step:
- The
html_panelcapability indicates the ability to display HTML provided by the panel. This HTML can reference pre-defined classes and widgets that permit linking into files and other modes of interaction. - The
file_commentcapability indicates the editor will permit comments to be displayed on specific lines of the file. - The
ide_operationcapability family indicates the editor can provide various IDE operations ("get-selection", "find-all-references", etc).
The Symposium VSCode extension is the prototype Symposium editor
Symposium's VSCode extension will serve as the prototype Symposium editor, supporting all the above capabilities. It will create a "terminal-like" window based, initially, on the (Apache-2.0 licensed) editor from continue.dev that allows communication with the agent. When the agent sends walkthroughs or requests IDE support, they are provided by the editor.
Bridging to ACP agents
The ToAgent convert allows converting a "plain ACP" agent into an SCP agent. ACP agents do not support the full capabilities of SCP agents (see the implementation section for details) but they do support the ability for SCP proxies to define MCP tools; this is needed to support walkthroughs and collaborator identities. This support works by creating a "shim" MCP tool that receives input over stdio and communicates it via side-channel back to the ToAgent actor, which can then send SCP messages backwards.
Bridging to ACP editors
While not planned for initial implementation, it should be possible to bridge an SCP proxy chain to an ACP editor by providing a ToEditor transformer that initializes the proxy chain (based on some undefined source of configuration) but without the extended capabilities (walkthroughs, etc). This would permit Symposium to be used in (e.g.) Zed. However, a preferred route would be to contribute full Symposium support upstream to Zed.
Shiny future
How will things will play out once this feature exists?
Composable Development Experience
SCP enables users to mix and match development capabilities. Interactive walkthroughs display as HTML panels with inline code comments. Collaboration patterns adapt to individual working styles. A developer can add a "research assistant" proxy to their chain and gain research capabilities while keeping existing walkthroughs and collaboration patterns.
Upstreaming to ACP
As SCP proves useful, these extensions can be contributed to the ACP specification. Rich content blocks, capability negotiation, and proxy chaining would become standard ACP features, eliminating the need for adapter components. Existing SCP components would work unchanged, communicating over native ACP.
User-Defined Tool Composition
Users will define their own development environments by composing proxy components. A Rust developer might configure crate-analysis, documentation-generation, and performance-profiling proxies. A web developer might prefer TypeScript-analysis, accessibility-checking, and deployment-automation proxies. This creates a marketplace where specialized components can be developed, shared, and combined.
Multiple Active Agents
SCP supports multiple agents working simultaneously within a taskspace. A user might have a coding agent for implementation, a research agent for investigation, and a review agent for quality analysis. These agents coordinate through the proxy chain, sharing context and handing off tasks.
Context-Aware Proxy Selection
SCP could automatically configure proxy chains based on project context. A Rust project with async dependencies might include async-analysis and tokio-debugging proxies. A web project with accessibility requirements might include WCAG-compliance and screen-reader-testing proxies. This reduces setup overhead while ensuring developers have appropriate capabilities for their projects.
Future Extensions: Advanced features like session state manipulation (for tangent mode) and conversation history modification will require additional protocol extensions for proxy coordination. These capabilities will be designed as the ecosystem matures.
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
TODO: Add concrete implementation plan with phases and deliverables.
SCP protocol
Definition: Editor vs Agent of a proxy
For an SCP proxy, the "editor" is defined as the upstream connection and the "agent" is the downstream connection.
flowchart LR
Editor --> Proxy --> Agent
SCP editor capabilities
An SCP-aware editor provides the following capability during ACP initialization:
/// Including the symposium section *at all* means that the editor
/// supports symposium proxy initialization.
"_meta": {
"symposium": {
"version": "1.0",
"html_panel": true, // or false, if this is the ToEditor proxy
"file_comment": true, // or false, if this is the ToEditor proxy
}
}
SCP proxies forward the capabilities they receive from their editor.
SCP agent capabilities
An SCP-aware agent or proxy provides the following capability during ACP initialization:
/// Including the symposium section *at all* means that the editor
/// supports symposium proxy initialization.
"_meta": {
"symposium": {
"version": "1.0",
"proxy": true, // false if this is not an SCP proxy and therefore does not expect a proxy chain
}
}
The proxy flag indicates whether this SCP server is a proxy or a final agent:
- An SCP agent (
proxy = false) is the final node in the chain. It behaves like an ACP server except that it supports MCP tools over SCP and other future SCP extensions. - An SCP proxy (
proxy = true) is an intermediate node in the chain. Proxies expect to be initialized with a_scp/proxyrequest before they can be used. Until the_scp/proxychain is established, any other requests result in an error. Once established, the proxy chain cannot be changed.
The _scp/proxy request
The _scp/proxy request contains an array of ScpServer structures. These structures follow the same format as ACP's McpServer specification, with only stdio transport mode supported initially. This allows proxies to launch and connect to their downstream components using the same patterns established by ACP.
The proxy handles launching and connecting to downstream SCP servers using the same mechanisms it would use for MCP servers. This reuses existing process management and communication patterns while extending them for the proxy chain architecture.
MCP tools over SCP
SCP extends the ACP protocol to allow MCP tools to be provided by proxies in the chain rather than only by the final agent. This enables proxies to offer interactive capabilities while maintaining compatibility with the existing MCP ecosystem.
SCP Transport Extension: When an agent advertises support for "symposium", the ACP McpServer structure is extended with a new transport type: { "type": "scp", "name": "..." }. This transport type indicates that the MCP server is provided by a proxy in the SCP chain rather than by an external process.
Message Forwarding: When the agent invokes an MCP tool using the "scp" transport, the message is forwarded to the ACP editor as an _scp/mcp request. The request contains an object {"name": "...", "message": M} that embeds the original MCP message M along with the name of the target proxy. This allows the editor to route the message to the appropriate proxy in the chain.
Bidirectional Communication: This mechanism enables full MCP protocol support through the proxy chain, including tool invocation, resource access, and prompt templates. Proxies can provide MCP tools that appear transparent to the agent while actually being handled by components earlier in the chain.
Bridging MCP to ACP
The ToAgent bridge component handles the translation between SCP's proxy-provided MCP tools and traditional ACP agents that expect stdio-based MCP servers.
Transport Translation: The bridge converts "scp" transport MCP servers into stdio transport by providing a dummy binary that acts as a shim. When the ACP agent attempts to invoke an MCP tool, it launches this dummy binary as it would any other MCP server.
IPC Forwarding: The dummy binary uses inter-process communication to forward MCP messages back to the ToAgent bridge, which then routes them through the SCP chain to the appropriate proxy. This maintains the agent's expectation of stdio-based MCP communication while enabling the proxy architecture.
Compatibility: From the agent's perspective, proxy-provided MCP tools appear identical to traditional MCP servers. This ensures compatibility with existing ACP agents while unlocking the composable capabilities of the SCP ecosystem.
HTML panels
HTML panels provide a content display mechanism that extends beyond simple text-based chat interactions. Panels are persistent, updateable UI elements that can display structured information alongside the conversation.
Panel Management: If the editor provides the html_panel capability, agents can manage panels through three core operations:
-
Show/Update Panel: The
_scp/html_panel/showmessage creates or updates a panel:{ "id": "$UUID", ("label": "text")?, ("contents": "...html...")? }. If a panel with the given ID already exists, it updates the provided fields (label and/or contents) and brings the panel to the front. For new panels, both label and contents must be provided or the message results in an error. -
Clear Panel: The
_scp/html_panel/clearmessage removes a panel:{ "id": "$UUID" }. This allows agents to clean up panels that are no longer needed. -
Query Panel: The
_scp/html_panel/getmessage retrieves current panel state:{ "id": "$UUID" }. This returns either null (if the panel doesn't exist) or the current contents, enabling agents to check panel state before updates.
Widget Support: Panels can contain interactive widgets that provide structured ways for users to interact with the content. This enables interfaces beyond static HTML display.
File comments
File comments enable agents to place contextual annotations directly in source code, creating a more integrated development experience than separate chat windows.
Comment Placement: If the editor provides the file_comment capability, agents can place comments using the _scp/file_comment/show message: { "id": "$UUID", "url": "...", "start": {"line": L, ("column": C)? }, ("end": {"line": L, ("column": C)?})?, "can_reply": boolean }.
Position Specification: Comments are positioned using line and column coordinates. If the start column is omitted, it defaults to the beginning of the line. If the end column is omitted, it defaults to the end of the line. If the end position is entirely omitted, the comment spans from the start position to the end of that line.
Interactive Comments: The can_reply flag determines whether the comment includes user interaction capabilities. When true, users can reply to the comment, creating a threaded discussion directly in the code. This enables collaborative code review and explanation workflows.
Logging
SCP provides a logging capability that enables observability and testing throughout the proxy chain. This allows proxies and agents to send structured log messages that can be captured by the editor for debugging, testing, and monitoring purposes.
Log Messages: Agents and proxies can send _scp/log messages upstream: { "level": "info|warn|error|debug", "message": "...", ("data": {...})? }. The editor receives these messages and can display them in output panels, write them to log files, or use them for test assertions.
Testing Integration: The logging capability is particularly valuable for scenario-based testing, where test frameworks can assert on expected log patterns to verify proxy behavior and message flow through the chain.
Implementation progress
What is the current status of implementation and what are the next steps?
Phase 1: TypeScript ACP Server + Test Harness
Status: Not started
Goal: Build and test basic ACP communication with fast iteration cycle.
Architecture: TypeScript ACP Server (standalone)
Implementation:
- Build dummy ACP server in TypeScript using
@zed-industries/agent-client-protocol - Create test harness that can directly import and test server logic
- Implement basic
initialize,newSession,prompthandlers
Key Test: basic-echo.test.ts
- Send "Hello, world" → get "Hello, user" response
- Validates ACP protocol implementation and basic message flow
- No compilation step needed - fast test iteration
Phase 2: Continue.dev GUI Integration
Status: Not started
Goal: Connect Continue.dev GUI to TypeScript ACP server through VSCode extension.
Architecture: Continue.dev GUI ↔ VSCode Extension (TypeScript ACP client) ↔ TypeScript ACP Server
Implementation:
- Integrate Continue.dev React GUI into VSCode extension webview
- Use TypeScript ACP client to spawn and communicate with server subprocess
- Implement Continue.dev message protocol translation to ACP
Key Test: Manual verification + log inspection
- Type in Continue.dev GUI → see ACP messages in VSCode output logs → response appears in GUI
- Validates full GUI ↔ server communication chain
Phase 3: ToAgent Bridge (Rust)
Status: Not started
Goal: Build the critical SCP-to-ACP bridge component that enables MCP tool forwarding.
Architecture: VSCode Extension ↔ ToAgent Bridge (Rust) ↔ TypeScript Dummy Agent
Implementation:
- Build ToAgent bridge in Rust that implements SCP protocol
- Convert "scp" transport MCP tools to stdio transport (dummy shim binaries)
- Handle
_scp/mcpmessage routing between extension and downstream agent - Forward standard ACP messages bidirectionally
Key Test: mcp-bridge.test.ts
- Send "hi" → agent invokes MCP tool → bridge routes
_scp/mcpto extension → tool logs "I got this message: Hi" → responds "Hola" - Validates MCP-over-SCP architecture and message routing
Phase 4: IDE Operations Proxy (Rust)
Status: Not started
Goal: Port existing IDE operations to Rust SCP proxy architecture.
Architecture: VSCode Extension ↔ IDE Operations Proxy (Rust) ↔ ToAgent Bridge ↔ Dummy Agent
Implementation:
- Port IDE operations from existing Symposium MCP server to Rust SCP proxy
- Implement file operations, code navigation, selection handling
- Insert proxy between extension and ToAgent bridge
Key Test: ide-operations.test.ts
- Request file operations → proxy handles IDE calls → logs show successful operations
- Validates Rust proxy architecture with real functionality
Phase 5: Walkthrough Proxy (Rust)
Status: Not started
Goal: Implement rich content capabilities with HTML panels and file comments.
Architecture: VSCode Extension ↔ Walkthrough Proxy (Rust) ↔ IDE Operations Proxy ↔ ToAgent Bridge ↔ Dummy Agent
Implementation:
- Build walkthrough proxy that generates
_scp/html_panel/showand_scp/file_comment/showmessages - Implement walkthrough markdown parsing and content generation
- Handle user interactions with panels and comments
Key Test: walkthrough-display.test.ts
- Request walkthrough → HTML panel appears in VSCode → file comments placed in editor
- Validates full SCP rich content capabilities end-to-end
Testing Strategy
Scenario-Based Testing:
- Each test is a directory containing mock agent scripts and test files
- Tests instantiate SCP proxy chains with mock agents as final components
- VSCode extension logs all key events to Output window for test assertions
- BDD-style tests: "when user says X, expect these log messages"
Test Structure:
test-scenarios/
├── basic-echo/
│ ├── agent.ts (TypeScript mock agent)
│ └── basic-echo.test.ts
├── mcp-bridge/
│ ├── agent.ts
│ └── mcp-bridge.test.ts
└── walkthrough-display/
├── agent.ts
└── walkthrough-display.test.ts
Observability: All components use _scp/log messages for structured logging, enabling test assertions on expected behavior patterns.
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
What alternative approaches did you consider, and why did you settle on this one?
We considered extending MCP directly, but MCP is focused on tool provision rather than conversation flow control. We also looked at building everything as VSCode extensions, but that would lock us into a single editor ecosystem.
SCP's proxy chain approach provides the right balance of modularity and compatibility - components can be developed independently while still working together.
How does this relate to other agent protocols like Google's A2A?
SCP is complementary to protocols like A2A. While A2A focuses on agent-to-agent communication for remote services, SCP focuses on composing the user-facing development experience. You could imagine SCP components that use A2A internally to coordinate with remote agents.
What about security concerns with arbitrary proxy chains?
Users are responsible for the proxies they choose to run, similar to how they're responsible for the software they install. Proxies can intercept and modify all communication, so trust is essential. For future versions, we're considering approaches like Microsoft's Wassette (WASM-based capability restrictions) to provide sandboxed execution environments.
Why reuse Continue.dev's GUI instead of building our own?
Continue.dev has already solved the hard problems of building a production-quality chat interface for VS Code extensions. Their GUI is specifically designed to be reusable - they use the exact same codebase for both VS Code and JetBrains IDEs by implementing different adapter layers.
Their architecture proves that message-passing protocols can cleanly separate GUI concerns from backend logic, which aligns perfectly with SCP's composable design. Rather than rebuilding chat UI, message history, streaming support, and context providers from scratch, we can focus our effort on the novel SCP protocol and proxy architecture.
The Apache 2.0 license makes this legally straightforward, and their well-documented message protocols provide a clear integration path.
Why not just use hooks or plugins?
Hooks are fundamentally limited to what the host application anticipated. SCP proxies can intercept and modify the entire conversation flow, enabling innovations that the original tool designer never envisioned. This is the difference between customization and true composability.
What about performance implications of the proxy chain?
The proxy chain does add some latency as messages pass through multiple hops. However, we don't expect this to be noticeable for typical development workflows. Most interactions are human-paced rather than high-frequency, and the benefits of composability outweigh the minimal latency cost.
How will users discover and configure proxy chains?
This will be determined over time as the ecosystem develops. We expect solutions to emerge organically, potentially including registries, configuration files, or marketplace-style discovery mechanisms.
What about resource management with multiple proxy processes?
Each proxy manages the lifecycle of processes it starts. When a proxy terminates, it cleans up its downstream processes. This creates a natural cleanup chain that prevents resource leaks.
Revision history
Initial draft based on architectural discussions.
Elevator pitch
What are you proposing to change?
Enable AI agents to run persistently in the background, surviving terminal disconnections and VSCode restarts. Agents would continue working on tasks asynchronously and can be attached/detached at will, similar to tmux sessions but with full integration into the Symposium ecosystem.
Status quo
How do things work today and what problems does this cause? Why would we change things?
Currently, AI agents (Q CLI, Claude Code) run synchronously in terminal sessions within VSCode. When the user:
- Closes VSCode → Agent dies, losing context and stopping work
- Terminal crashes → Agent dies, work is interrupted
- Disconnects from SSH → Remote agents die
- Switches between projects → Must restart agents from scratch
This creates several problems:
- No background work: Agents can't continue tasks while user is away
- Fragile sessions: Any disconnection kills the agent and loses progress
- Context loss: Restarting agents means rebuilding understanding of the project
- Poor multitasking: Can't work on multiple projects simultaneously with persistent agents
- SSH limitations: Remote development is unreliable due to connection issues
The current synchronous model treats agents like traditional CLI tools, but AI agents are more like long-running services that benefit from persistence.
What we propose to do about it
What are you proposing to improve the situation?
Implement a persistent agent system that:
- Wraps agents in tmux sessions - Each agent runs in a dedicated tmux session that survives disconnections
- Provides session management - Commands to spawn, list, attach, detach, and kill agent sessions
- Maintains agent metadata - Track session state, working directories, and agent types
- Integrates with VSCode - Seamless attach/detach from VSCode terminals
- Supports multiple agents - Run different agents (Q CLI, Claude Code, etc.) simultaneously
- Preserves conversation history - Agents maintain context across attach/detach cycles
The system builds on the existing tmux-based architecture we've already implemented, extending it with better lifecycle management and VSCode integration.
Shiny future
How will things will play out once this feature exists?
Background work scenario:
- User starts agent on a refactoring task, then goes to lunch
- Agent continues working, making commits and progress
- User returns, attaches to see what was accomplished
- Agent provides summary of work done while disconnected
Multi-project workflow:
- User has 3 projects with persistent agents running
- Switches between projects by attaching to different agent sessions
- Each agent maintains full context of its project
- No startup time or context rebuilding when switching
Reliable remote development:
- SSH connection drops during remote development
- Agent continues running on remote server
- User reconnects and reattaches to same agent session
- No work lost, agent picks up where it left off
Collaborative handoffs:
- Team member starts agent working on a feature
- Hands off session to another team member
- Second person attaches to same agent session
- Full context and conversation history preserved
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
Phase 1: Core Infrastructure ✅ (Completed)
- Agent Manager with tmux session spawning
-
Session metadata persistence (
~/.symposium/agent-sessions.json) - Basic lifecycle commands (spawn, list, attach, kill)
- Status tracking and sync with tmux reality
Phase 2: VSCode Integration (Current)
-
Seamless attach/detach from VSCode
- VSCode command to attach to persistent agent
- Automatic terminal creation and tmux attach
- Status indicators showing which agents are running
-
Agent discovery and selection
- UI to browse available persistent agents
- Show agent status, working directory, last activity
- Quick attach buttons in VSCode interface
-
Session lifecycle integration
- Spawn agents directly from VSCode taskspace creation
- Automatic cleanup when projects are deleted
- Handle agent crashes gracefully
Phase 3: Enhanced Agent Experience
-
Conversation persistence improvements
- Ensure agents properly resume conversations in tmux
- Handle conversation history across detach/attach cycles
- Support for named conversations per agent
-
Background task queue
- Queue tasks for agents to work on while disconnected
- Progress reporting and completion notifications
- Integration with taskspace management
-
Multi-connection support
- Multiple users/terminals can connect to same agent
- Shared conversation view and collaboration
- Conflict resolution for simultaneous interactions
Phase 4: Advanced Features
-
Custom pty manager (Optional)
- Replace tmux with custom Rust implementation
- Better integration with Symposium ecosystem
- More control over session lifecycle
-
Agent orchestration
- Coordinate multiple agents working on same project
- Share context and results between agents
- Hierarchical task delegation
Technical Architecture
graph TB
VSCode[VSCode Extension] -->|spawn/attach| AgentManager[Agent Manager]
AgentManager -->|creates| TmuxSession[tmux Session]
TmuxSession -->|runs| AgentCLI[Agent CLI Tool]
AgentCLI -->|q chat --resume| MCPServer[MCP Server]
MCPServer -->|IPC| Daemon[Symposium Daemon]
AgentManager -->|persists| SessionFile[~/.symposium/agent-sessions.json]
VSCode -->|discovers| SessionFile
style TmuxSession fill:#e1f5fe
style AgentManager fill:#f3e5f5
style SessionFile fill:#e8f5e8
Success Criteria
- Agents survive VSCode restarts and terminal disconnections
- Seamless attach/detach experience from VSCode
- Conversation history preserved across sessions
- Multiple agents can run simultaneously
- Background work continues when user is disconnected
- Reliable operation over SSH connections
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
What alternative approaches did you consider, and why did you settle on this one?
Custom pty manager: We considered building a custom pseudo-terminal manager in Rust instead of using tmux. While this would give us more control, tmux is battle-tested, widely available, and handles the complex edge cases of terminal management. We can always migrate to a custom solution later.
Docker containers: We explored running agents in containers for better isolation. However, this adds complexity around file system access, authentication tokens, and development tool integration. The direct execution model with tmux provides better compatibility with existing workflows.
Background services: We considered running agents as system services or daemons. This would provide persistence but loses the interactive terminal experience that's valuable for debugging and manual intervention.
How does this interact with existing conversation history?
Agent CLI tools (Q CLI, Claude Code) already handle conversation persistence per working directory. The persistent agent system doesn't duplicate this - it relies on the agents' existing --resume functionality to restore conversation context when sessions are reattached.
What happens if tmux isn't available?
The system gracefully degrades to the current synchronous behavior. Commands that require tmux will fail with clear error messages directing users to install tmux or use the synchronous mode.
How do you handle agent crashes or hangs?
The Agent Manager syncs with tmux reality on startup and periodically, detecting crashed sessions and marking them appropriately. Users can kill hung sessions and spawn new ones. Future versions could include automatic restart policies and health monitoring.
Can multiple people attach to the same agent session?
tmux natively supports multiple connections to the same session. However, this can lead to conflicts if multiple people try to interact with the agent simultaneously. Future versions could add coordination mechanisms or separate read-only observation modes.
Revision history
- Initial draft: Created RFD based on existing implementation and planned enhancements
Elevator pitch
What are you proposing to change? Bullet points welcome.
Enable users to tile multiple taskspace windows so they can monitor progress across several tasks simultaneously, rather than switching between hidden windows.
Status quo
How do things work today and what problems does this cause? Why would we change things?
Currently, users can choose between "free windows" (taskspaces positioned anywhere) and "stacked" mode (where only one taskspace is visible at a time). While free windows allow multiple taskspaces to be visible, they can overlap and become disorganized. Stacked mode keeps things tidy but limits visibility to one taskspace. There's no middle ground that provides organized, non-overlapping visibility of multiple taskspaces simultaneously.
Shiny future
How will things will play out once this feature exists?
Users can choose a "grid" mode that creates multiple organized stacks - essentially a hybrid between free windows and stacked mode. Each grid cell contains a stack of taskspaces, allowing users to see several taskspaces simultaneously in a clean, non-overlapping layout. Users can configure the grid size (2x2, 1x3, etc.) and assign taskspaces to specific grid positions, providing organized visibility across multiple concurrent tasks.
Implementation plan
What is your implementaton plan?
NOTE: Do not bother with this section while the RFD is in "Draft" phase unless you've got a pretty clear idea how you think it should work and/or have things you particularly want to highlight. This will typically be authored and updated by an agent as implementation work proceeds.
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions? Keep this section up-to-date as discussion proceeds. The goal is to capture major points that came up on a PR or in a discussion forum -- and if they reoccur, to point people to the FAQ so that we can start the dialog from a more informed place.
What alternative approaches did you consider, and why did you settle on this one?
None. The idea came to me fully formed, like Athena springing from Zeus's head.
Revision history
If there have been major updates to this RFD, you can include the git revisions and a summary of the changes.
Elevator pitch
Add gitdiff elements to the walkthrough system to display interactive git diffs within walkthroughs, allowing agents to show code changes inline with explanatory content.
Status quo
Currently, when agents want to show code changes in walkthroughs, they have limited options:
- Reference code with comments, but can't show what changed
- Describe changes in text, which is less clear than visual diffs
- Ask users to manually check git history to understand changes
This makes it harder to create comprehensive walkthroughs that explain both the current state of code and how it evolved. When demonstrating development workflows or explaining implementation decisions, the lack of inline diff visualization breaks the narrative flow.
What we propose to do about it
Implement gitdiff elements in the walkthrough markdown format that render as interactive diff trees in VSCode. The syntax would be:
```gitdiff(range="HEAD~2..HEAD")
```gitdiff(range="abc123", exclude-unstaged, exclude-staged)
This would allow agents to seamlessly integrate git diffs into educational walkthroughs, showing exactly what code changed while explaining the reasoning behind those changes.
Shiny future
Agents will be able to create rich, educational walkthroughs that combine:
- Explanatory text and mermaid diagrams
- Interactive code comments
- Visual git diffs showing actual changes
- Seamless narrative flow from "here's what we built" to "here's how we built it"
This will make Symposium's learning capabilities much more powerful, especially for onboarding to new codebases or understanding complex changes.
Frequently asked questions
What alternative approaches did you consider, and why did you settle on this one?
We considered static code blocks with diff syntax highlighting, but interactive diffs provide much better user experience. We also considered linking to external git hosting, but keeping everything in the walkthrough maintains the narrative flow.
Revision history
- 2025-09-22: Initial draft
Elevator pitch
What are you proposing to change?
Using Symposium today requires creating a "Symposium project" which is a distinct checkout and space from the user's ongoing work. This RFD lays out a plan to modify Symposium so that it can be used on an existing checkout and be added directly to the user's workflows.
Status quo
How do things work today and what problems does this cause? Why would we change things?
Today, using Symposium requires creating a separate "Symposium project" that is distinct from the user's existing work:
Current Directory Structure
When users create a Symposium project, they get a structure like:
/path/to/symposium-projects/my-project/
├── .git/ # Bare clone of their repository (a bit unusual)
├── .symposium/
│ ├── project.json # Project configuration
│ └── task-$UUID/ # Individual taskspaces
│ ├── taskspace.json
│ └── my-project/ # Working copy for this taskspace
└── (other project files)
This creates a completely separate checkout from where the user normally works.
Current Setup Process
To try Symposium, users must:
- Fill out a project creation form with:
- Project name
- Git repository URL
- Local directory location
- AI agent configuration
- Have a cloneable repository - they can't experiment without existing git-hosted code
- Wait for git clone - Symposium creates its own fresh checkout
- Context switch - move from their normal working directory to the Symposium project directory
- Learn new concepts - understand projects vs taskspaces before getting value
Problems This Creates
Workflow disruption: Users must stop their current work and switch to a separate Symposium environment. This is disruptive and creates friction for adoption.
Setup barriers: The multi-step form and repository requirement prevent quick experimentation. Users can't just "try it on this code I'm looking at right now."
Cognitive overhead: Users must understand the Symposium project concept and directory structure before they can experience any value from AI collaboration.
Maintenance burden: Users end up with multiple checkouts of the same repository that can get out of sync or consume extra disk space.
What we propose to do about it
What are you proposing to improve the situation?
Replace the "create Symposium project" workflow with an "open existing project" approach that works directly on the user's current checkout:
New Project Opening Flow
- No splash screen needed - users go directly to "Open Project"
- Select existing git directory - point Symposium at where they're already working
- Automatic setup - if no
.symposiumdirectory exists:- Prompt user that we'll create one
- Modify
.gitignoreto exclude.symposium- Create a commit with just this one change and commit message "add symposium to gitignore" and "co-authored-by: socrates@symposium-dev.com"
- If there are already staged changes, unstage and restage I guess? Or just don't commit it.
- Create
.symposiumdirectory structure
New Directory Structure
Instead of a separate checkout, Symposium works in-place:
/home/dev/my-project/ # User's existing project
├── .git/ # Their existing git repository
├── .gitignore # Modified to include .symposium
├── .symposium/ # Symposium metadata (gitignored)
│ ├── project.json # project-wide configuration
│ ├── root-taskspace.json # taskspace description for the "root", created by default
│ └── taskspace-$UUID/
│ ├── taskspace.json
│ └── my-project/ # Working copy for this taskspace
└── (user's existing project files)
Root taskspace
Every project gets a default root-taskspace.json that works like any other taskspace but:
- Found at
.symposium/root-taskspace.jsoninstead of.symposium/taskspace-$UUID/taskspace.json - Cannot be deleted (ensures users always have a working space)
- Provides immediate usability without requiring taskspace creation
This means the code must handle both lookup patterns gracefully and enforce the deletion restriction for the root taskspace.
Other bits of auto-configuration
- We should auto-detect main branch
- Look for a remote that is a non-fork github and see what it's default push target is
- Failing that, present users with a choice
Shiny future
How will things will play out once this feature exists?
A developer working on their project decides to try Symposium:
- Opens Symposium and selects "Open Project"
- Points to their current directory - the one they're already working in
- Gets a simple prompt - "We'll add Symposium support to this project, okay?"
- Root taskspace launches automatically - opens with an agent that gets context about:
- Current unstaged changes in the working directory
- Recent commits that haven't been merged to main
- Standard "find out what the user wants to do" prompt
- Immediately starts collaborating - agent is aware of current work state
- Continues normal workflow - their existing tools, git history, and working directory remain unchanged
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
Let's begin migrating "business logic" out from the Swift code and into the Rust code to make it more portable. Let's extend the symposium-mcp command to have a new command, private -- ideally, undocumented. We can then add commands like
symposium-mcp private open-symposium-project --path "..."
which will do the work of initializing the directory and respond with a JSON structure.
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
Questions for discussion
Why do we create two subdirectories?
The reason we create this structure:
taskspace-$UUID/my-project
rather than just taskspace-$UUID is that it means that, within VSCode, the project appears as my-project and not a UUID.
Elevator pitch
What are you proposing to change?
Add the ability for taskspaces to choose a collaborator, rather than always using the same collaboration patterns. The existing behavior becomes the "socrates" collaborator.
Add two new collaborators: base-agent (no collaboration patterns, base agent) and sparkle (based on the Sparkle MCP server).
When the assemble_yiasou_prompt code runs, it will use the collaborator choice to decide what to do. For sparkle, it will instruct the LLM to execute the sparkle tool.
Both Symposium and Sparkle MCP servers are installed as separate binaries via cargo setup, making all tools from both servers available to the LLM at all times. The collaborator choice only affects prompt assembly and initialization behavior.
When a new taskspace is created, users have the option to specify the collaborator, with sparkle being the default. The spawn_taskspace MCP also now has an optional parameter to specify the collaborator which defaults to the same collaborator as the current taskspace.
The @hi command takes an optional parameter that is the collaborator name. It defaults to the taskspace's current collaborator setting, or sparkle if not in a taskspace.
Status quo
How do things work today and what problems does this cause? Why would we change things?
Currently, all Symposium taskspaces use the same collaboration patterns from main.md (Socratic dialogue approach). The /yiasou prompt assembly loads these patterns for every agent initialization, creating a one-size-fits-all collaboration style.
While the current Socratic patterns are an improvemegnt, Sparkle represents a more advanced collaboration framework with richer patterns, persistent memory, and specialized tools for partnership development.
Problems with current approach:
- Limited to basic collaboration patterns when more advanced options exist
- No access to Sparkle's advanced partnership tools and persistent memory
- No personalization of collaboration style per taskspace
- No way to experiment with different AI collaboration approaches
What we propose to do about it
What are you proposing to improve the situation?
Implement a collaborator system with three options: Implement a collaborator system with three options:
sparkle- Advanced collaboration patterns with persistent memory and partnership tools (the default!)socrates- Current Socratic dialogue patterns (zero-config fallback)base-agent- No collaboration patterns, base agent behavior (aliases:claude,gpt,gemini,codex)
Sparkle becomes the default because it provides strictly better collaboration patterns. Socrates remains available for the time being as a zero-config option.
Selection behavior:
- Within taskspaces:
@hiuses the taskspace's current collaborator setting,@hi <collaborator>changes it and updates the taskspace viaupdate_taskspace - Outside taskspaces:
@hidefaults to sparkle, but@hi socratesor@hi claude(or other base-agent aliases) available
Future extensibility will allow custom Sparkler names and user-defined collaborators.
Integration approach:
- Install both Symposium and Sparkle MCP servers as separate binaries via
cargo setup - Configure both servers in AI assistant MCP configurations
- Modify taskspace data structure to store collaborator choice
- Update
/yiasouprompt assembly to load appropriate patterns and execute sparkle tool for sparkle collaborator - Implement
@hi <collaborator>syntax for selection with taskspace persistence
Shiny future
How will things will play out once this feature exists?
Users can create taskspaces with different collaborators:
@hi sparklecreates a taskspace with Sparkle's embodiment patterns, working memory, and partnership tools@hi socratesuses the familiar Socratic dialogue approach@hi claude(or@hi gpt,@hi gemini, etc.) provides minimal AI collaboration for focused technical work
Each taskspace maintains its collaborator choice, creating consistent collaboration experiences. Sparkle taskspaces gain access to Sparkle's advanced collaboration tools and persistent memory features.
The system becomes a platform for experimenting with different AI collaboration approaches while maintaining backward compatibility.
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
Technical Architecture
Dual MCP Servers: Install both Symposium and Sparkle as separate MCP server binaries via cargo setup:
- Both servers configured in the AI assistant's MCP configuration
- All tools from both servers are always available to the LLM
- No dynamic tool routing or conditional tool exposure needed
- Simpler architecture with standard MCP server setup
Sparkle Integration: Install Sparkle MCP server via cargo install --git:
- Sparkle tools: All tools from the Sparkle MCP server (e.g.,
sparkle,session_checkpoint, etc.) - Sparkle directories:
~/.sparkle/(global patterns/insights),.sparkle-space/(workspace working memory)
Prompt Assembly: /yiasou prompt assembly varies by collaborator:
sparkle→ Load Sparkle identity files + instruct LLM to executesparkletool for initializationsocrates→ Load existing Socratic dialogue patterns fromsocrates.md(renamed frommain.md)base-agent→ Load minimal patterns, no special initialization
Current System Integration:
- Existing guidance (
symposium/mcp-server/src/guidance/main.md) becomes "socrates" collaborator (rename tosocrates.md) - Add
collaborator: Option<String>field to taskspace data structure - Layer collaborator system on top of existing
AgentManager/AgentTypearchitecture
Phase 1: Dual MCP Server Installation
- Update
cargo setupto install Sparkle MCP server viacargo install --git https://github.com/symposium-dev/sparkle.git --root sparkle-mcp - Add
build_and_install_sparkle_cli()function tosetup/src/main.rssimilar tobuild_and_install_rust_server() - Configure both Symposium and Sparkle MCP servers in AI assistant configurations
- All tools from both servers available to LLM
Phase 2: Collaborator System
- Add
collaborator: Option<String>to taskspace data structure - Modify
/yiasouprompt assembly to conditionally load:sparkle→ Sparkle identity files + executesparkletoolsocrates→ existingsocrates.md(renamed frommain.md)base-agent→ minimal patterns
- Parse
@hi <collaborator>syntax in initial prompts, supporting aliases (claude,gpt,gemini,codex→base-agent) - When
@hi <collaborator>used in taskspace, instruct LLM to callupdate_taskspaceto persist collaborator choice
Phase 3: Tool Integration
- Ensure all Sparkle tools work properly with dual MCP server setup
- Handle Sparkle-specific directories (
~/.sparkle/,.sparkle-space/) - Verify tool functionality across different collaborator modes
Phase 4: Crates.io Migration
- Publish
sparkle-mcpto crates.io - Switch from path dependency to crates.io dependency
- Remove git submodule once crate dependency is stable
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
What alternative approaches did you consider, and why did you settle on this one?
Alternative approaches considered:
- Separate MCP servers: Run Sparkle and Symposium as separate MCP servers, but this would complicate tool coordination and user experience
- Dynamic tool routing: Conditionally expose tools based on collaborator choice, but this adds complexity for managing tool availability
- Configuration files: Store collaboration patterns in config files, but this lacks the rich tooling and state management that Sparkle provides
- Plugin system: Create a general plugin architecture, but this adds complexity for a specific integration need
The embedded MCP servers approach provides the simplest integration - all tools are always available, and the collaborator choice only affects prompt assembly and initialization behavior.
How will this affect existing taskspaces?
Existing taskspaces will continue using the current Socratic patterns by default. The socrates collaborator will be equivalent to current behavior, ensuring backward compatibility. All users will have access to Sparkle tools, but they'll only be used when the sparkle collaborator is active.
What happens to custom Sparkler names?
The initial implementation will use the default "sparkle" name. Custom Sparkler names (like @hi alice) can be added in a future iteration once the basic system is working.
Revision history
Initial version - October 8, 2025 Updated to embedded MCP servers approach - October 8, 2025
Preview
Preview features are 'feature complete' in their implementation and seeking testing and feedback.
Elevator pitch
What are you proposing to change? Bullet points welcome.
- Fix agent confusion when taskspace deletion is cancelled by user
- Implement deferred IPC responses that wait for actual user confirmation
- Ensure agents receive accurate feedback about deletion success/failure
Status quo
How do things work today and what problems does this cause? Why would we change things?
Today when an agent requests taskspace deletion:
- Agent calls
delete_taskspacetool - System immediately responds "success"
- UI shows confirmation dialog to user
- User can confirm or cancel, but agent already thinks deletion succeeded
Problem: Agents refuse to continue work because they assume the taskspace is deleted, even when the user cancelled the deletion dialog.
Shiny future
How will things will play out once this feature exists?
When an agent requests taskspace deletion:
- Agent calls
delete_taskspacetool - System shows confirmation dialog (no immediate response)
- If user confirms → actual deletion → success response to agent
- If user cancels → error response to agent ("Taskspace deletion was cancelled by user")
Result: Agents get accurate feedback and can continue working when deletion is cancelled.
Implementation plan
What is your implementaton plan?
Status: ✅ IMPLEMENTED
- Added
MessageHandlingResult::pendingcase for deferred responses - Store pending message IDs in ProjectManager until dialog completes
- Send appropriate success/error response based on user choice
- Updated IPC handler to support pending responses
- Updated UI dialog handlers to send deferred responses
Implementation details: See taskspace-deletion-dialog-confirmation branch and related documentation updates.
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions? Keep this section up-to-date as discussion proceeds. The goal is to capture major points that came up on a PR or in a discussion forum -- and if they reoccur, to point people to the FAQ so that we can start the dialog from a more informed place.
What alternative approaches did you consider, and why did you settle on this one?
The deferred response pattern was the most straightforward solution that maintains backward compatibility while fixing the core issue. Alternative approaches like immediate cancellation or optimistic responses would have been more complex and potentially confusing.
Could this pattern be applied to other confirmation dialogs?
Yes, the MessageHandlingResult::pending pattern is reusable for any operation that requires user confirmation before completing.
Revision history
Initial version documenting the implemented dialog confirmation functionality.
Elevator pitch
What are you proposing to change?
Extend Symposium with a new get_rust_crate_source MCP tool that will direct agents to the sources from Rust crates and help to find examples of code that uses particular APIs.
Status quo
How do things work today and what problems does this cause? Why would we change things?
When Rust developers ask an agent to use a crate that they do not know from their training data, agents typically hallucinate plausible-seeming (but in fact nonexistent) APIs. The easiest way to help an agent get started is to find example code and/or to point them at the crate source, which currently requires manual investigation or the use of a separate (and proprietary) MCP server like context7.
Leverage Rust's existing examples and rustdoc patterns
Cargo has conventions for giving example source code:
- many crates use the
examplesdirectory - other crates include (tested) examples from rustdoc
Our MCP server will leverage those sources.
What we propose to do about it
What are you proposing to improve the situation?
Integrate Rust crate source exploration capabilities directly into the Symposium MCP server through a unified get_rust_crate_source tool that:
- Extracts crate sources to a local cache directory for exploration
- Matches versions with the current Rust crate
Cargo.toml, if the crate is in use; otherwise gets the most recent version - Accepts optional version parameter as a semver range (same format as
Cargo.toml) to override version selection - Optionally searches within the extracted sources using regex patterns
- Returns structured results with file paths, line numbers, and context
- Provides conditional responses - only includes search results when a pattern is provided
- Caches extractions to avoid redundant downloads and improve performance
This eliminates the need for separate MCP servers and provides seamless integration with the existing Symposium ecosystem.
Shiny future
How will things will play out once this feature exists?
When developers ask the agent to work with a crate that they do not know, they will invoke the get_rust_crate_source MCP tool and read in the crate source. The agent will be able to give the names of specific APIs and provide accurate usage examples. Developers working in Symposium will have seamless access to Rust crate exploration:
- Unified Interface: Single
get_rust_crate_sourcetool handles both extraction and searching - IDE Integration: Results appear directly in the IDE with proper formatting and links
- Intelligent Responses: Tool returns only relevant fields (search results only when pattern provided)
- Cached Performance: Extracted crates are cached to avoid redundant downloads
- Rich Context: Search results include surrounding code lines for better understanding
Example workflows:
get_rust_crate_source(crate_name: "tokio")→ extracts and returns path infoget_rust_crate_source(crate_name: "tokio", pattern: "spawn")→ extracts, searches, and returns matches
Implementation details and plan
Tell me more about your implementation. What is your detailed implementaton plan?
Details
Tool parameters
The get_rust_crate_source tool accepts the following parameters:
{
"crate_name": "string", // Required: Name of the crate (e.g., "tokio")
"version": "string?", // Optional: Semver range (e.g., "1.0", "^1.2", "~1.2.3")
"pattern": "string?" // Optional: Regex pattern for searching within sources
}
Tool result
The response always begins with the location of the crate source:
{
"crate_name": "tokio",
"version": "1.35.0",
"checkout_path": "/path/to/extracted/crate",
"message": "Crate tokio v1.35.0 extracted to /path/to/extracted/crate"
}
When a pattern is provided, we include two additional fields, indicating that occured in examples and matches that occurred anywhere:
{
// ... as above ...
// Indicates the matches that occurred inside of examples.
"example_matches": [
{
"file_path": "examples/hello_world.rs",
"line_number": 8,
"context_start_line": 6,
"context_end_line": 10,
"context": "#[tokio::main]\nasync fn main() {\n tokio::spawn(async {\n println!(\"Hello from spawn!\");\n });"
}
],
// Indicates any other matches that occured across the codebase
"other_matches": [
{
"file_path": "src/task/spawn.rs",
"line_number": 156,
"context_start_line": 154,
"context_end_line": 158,
"context": "/// Spawns a new asynchronous task\n///\npub fn spawn<T>(future: T) -> JoinHandle<T::Output>\nwhere\n T: Future + Send + 'static,"
}
],
}
Crate version and location
The crate version to be fetched will be identified based on the project's lockfile, found by walking up the directory tree from the current working directory. If multiple major versions of a crate exist in the lockfile, the tool will return an error requesting the agent specify which version to use via the optional version parameter. When possible we'll provide the source from the existing cargo cache. If no cache is found, or the crate is not used in the project, we'll download the sources from crates.io and unpack them into a temporary directory.
The tool accepts an optional version parameter as a semver range (using the same format as Cargo.toml, e.g., "1.0", "^1.2", "~1.2.3") and will select the most recent version matching that range, just as cargo would.
Impl phases
Phase 1: Core Integration ✅ (Completed)
- Copy
eglibrary source intosymposium/mcp-server/src/eg/ - Add required dependencies to Cargo.toml
- Implement unified
get_rust_crate_sourcetool with conditional response fields - Fix import paths and module structure
Phase 2: Testing and Documentation
- Create comprehensive test suite for the tool
- Update user documentation with usage examples
- Create migration guide for existing standalone
egusers - Performance testing and optimization
Phase 3: Enhanced Features (Future)
- Configurable context lines for search results
- Search scope options (examples only vs. all source)
- Integration with other Symposium tools for enhanced workflows
- Smart dependency resolution (use the version that the main crate being modified depends on directly)
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
Why not use rustdoc to browse APIs?
We have observed that most developers building in Rust get good results from manually checking out the sources. This fits with the fact that agents are trained to work well from many-shot prompts, which are essentially a series of examples, and that they are trained to be able to quickly read and comprehend source code.
It is less clear that they are good at reading and navigating rustdoc source, but this is worth exploring.
Why not use LSP to give structured information?
See previous answer -- the same logic (and desire to experiment!) applies.
Won't checking out the full crate source waste a lot of context?
Maybe -- the impl details may not be especially relevant, but then again,when I want to work with crates, I often drill in. We might want to explore producing altered versions of the source that intentionally hide private functions and so forth, and perhaps have the agent be able to ask for additional data.
How will we ensure the agent uses the tool?
This is indeed a good question! We will have to explore our guidance over time, both for steering the agent to use the tool and for helping it understand the OUTPUT.
What future enhancements might we consider?
- Smart dependency resolution: Instead of erroring on version conflicts, use the version that the main crate being modified depends on directly
- Workspace-aware version selection: Handle complex workspace scenarios with multiple lockfiles
- Integration with rust-analyzer: Leverage LSP information for more targeted source exploration
- Filtered source views: Hide private implementation details to reduce context noise
Revision history
- 2025-09-17: Initial RFD creation with completed Phase 1 implementation
To be removed (yet?)
These are RFDs that we have decided not to accept, but we haven't done the work to fully remove yet.
Completed
RFDs that have been accepted and where work is completed.
Elevator pitch
What are you proposing to change? Bullet points welcome.
Introduce a "Request for Dialog" (RFD) process to replace ad-hoc design discussions with structured, community-friendly design documents that track features from conception to completion.
Status quo
How do things work today and what problems does this cause? Why would we change things?
Currently all development is being done by nikomatsakis and tracking documents are scattered all over the place. The goal is to create a process that helps to keep files organized and which can scale to participation by an emerging community.
Shiny future
How will things will play out once this feature exists?
Project licensing
All code and RFDs are dual-licensed under a MIT and Apache 2.0 license. The project is intended to remain open source and freely available in perpetuity. By agreeing to the MIT licensing, contributors agree that the core team may opt to change this licensing to another OSI-approved open-source license at their discretion in the future should the need arise.
Decision making
For the time being, the project shall have a "design team" with 1 member, nikomatsakis, acting in "BDFL" capacity. The expectation is that the project will setup a more structure governance structure as it grows. The design team makes all decisions regarding RFDs and sets overall project direction.
RFD lifecycle
RFDs are proposed by opening a PR
An RFD begins as a PR adding a new file into the "Draft" section. The RFD can start minimal - just an elevator pitch and status quo are enough to begin dialog. Pull requests become the discussion forum where ideas get refined through collaborative iteration.
As discussion proceeds, the FAQ of the RFD should be extended. If discussion has been going long enough, the PR should be closed, feedback summarized, and then re-opened with a link to the original PR.
The PR is merged into "draft" once a core team member decides to champion it
RFD proposals are merged into the "draft" section if a core team member decides to champion them. The champion is then the point-of-contact for that proposal going forward and they will work with the proposal authors and others to make it reality. Core team members do not need to seek consensus to merge a proposal into the draft, but they should listen carefully to concerns from other core team members, as it will be difficult to move the RFD forward if those concerns are not ultimately addressed.
Once a proposal is moved to draft, code and implementation may begin to land into the PR. This work needs to be properly feature gated and marked with the name of the RFD.
Further discussion on the RFD can take place on Zulip.
Moving to the "preview" section
Once the champion feels the RFD is ready for others to check it out, they can open a PR to move the file to the preview section. This is a signal to the community (and particularly other core team members) to check out the proposal and see what they think. The PR should stay open for "a few days" to give people an opportunity to leave feedback. The champion is empowered to decide whether to land the PR. As ever, all new feedback should be recorded in the FAQ section.
Deciding to accept an RFD
When they feel the RFD is ready to be completed, the champion requests review by the team. The team can raise concerns and notes during discussion. Final decision on an RFD is made by the core team lead.
Implementation of an RFD
Once accepted, RFDs become living documents that track implementation progress. Status badges in design documentation link back to the relevant RFD, creating a clear connection between "why we're building this" and "how it works." When building code with an agent, agents should read RFDs during implementation to understand design rationale and update them with implementation progress.
Moderating and managing RFD discussions
Moving RFDs between points in the cycle involve opening PRs. Those PRs will be places to hold people dialog and discussion -- but not the only place, we expect more detailed discussions to take place on Zulip. RFD owners and champions should actively "curate" discussions by collecting questions that come up and ensuring they are covered in the FAQ. Duplicate questions can be directed to the FAQ.
If the discussion on the PR gets to the point where Github begins to hide comments, the PR should typically be closed, feedback collected, and then re-opened.
Implementation plan
What is your implementaton plan?
- ✅ Create RFD infrastructure (README, template, SUMMARY.md sections)
- ✅ Establish lifecycle: Draft → Preview → Accepted → Completed
- ⏳ Connect status badges to RFDs
- ⏳ Write RFDs for major in-progress features
- ⏳ Document community contribution process
Frequently asked questions
So...there's a BDFL?
Yes. Early in a project, a BDFL is a good fit to maintain velocity and to have a clear direction.
So...why does this talk about a core team?
I am anticipating that we'll quickly want to have multiple designers who can move designs forward and not funnel everything through the "BDFL". Therefore, I created the idea of a "design team" and made the "BDFL" the lead of that team. But I've intentionally kept the final decision about RFDs falling under the lead, which means fundamentally the character of Symposium remains under the lead's purview and influence. I expect that if the project is a success we will extend the governance structure in time but I didn't want to do that in advance.
Why "Request for Dialog" and not "Request for Comment"?
Well, partly as a nod to Socratic dialogs, but also because "dialog" emphasizes conversation and exploration rather than just collecting feedback on a predetermined design. It fits better with our collaborative development philosophy.
Why not use Rust's RFC template as is?
We made some changes to better focus users on what nikomatsakis considers "Best practice" when authoring RFCs. Also because the new names seem silly and fun and we like that.
Why are you tracking the implementation plan in the RFD itself?
We considered using GitHub issues for design discussions, but RFDs living in-repo means agents can reference them during implementation.
Why not have RFD numbers?
It's always annoying to keep those things up-to-date and hard-to-remember. The slug-based filenames will let us keep links alive as we move RFDs between phases.
Revision history
- 2025-09-17: Initial version, created alongside RFD infrastructure
IPC Actor Refactoring
Status: ✅ COMPLETED (2025-09-21)
Implementation: The refactor introduced a RepeaterActor for centralized message routing, comprehensive unit tests, and debugging tools. See Debugging Tools for usage information.
Elevator pitch
What are you proposing to change? Bullet points welcome.
- Refactor the complex IPC code in
symposium/mcp-server/src/ipc.rsinto focused Tokio actors following Alice Ryhl's actor pattern - Split monolithic
IPCCommunicatorinto single-responsibility actors that communicate via channels - Extract daemon communication logic from the
daemonmodule into reusable channel-based actors - Make the system more testable by isolating concerns and enabling actor-level unit testing
Status quo
How do things work today and what problems does this cause? Why would we change things?
The current IPC system has several architectural issues:
Complex State Management: The IPCCommunicator struct manages multiple concerns in a single entity:
- Unix socket connection handling
- Message serialization/deserialization
- Pending reply tracking with timeouts
- Daemon discovery and reconnection logic
- Manual state synchronization with
Arc<Mutex<>>
Mixed Async Patterns: The code combines different async approaches inconsistently:
- Some functions use manual
Futureimplementations - Others use async/await
- State sharing relies on locks rather than message passing
Hard-to-Follow Message Flow: Message routing is embedded within the communicator logic, making it difficult to trace how messages flow through the system.
Testing Challenges: The monolithic structure makes it difficult to test individual components in isolation. Mock implementations require recreating the entire IPC infrastructure.
Recent Bug Example: We recently fixed a dialog confirmation bug where agents received immediate "success" responses even when users cancelled taskspace deletion. This happened because the complex state management made it hard to track the proper async flow.
Shiny future
How will things will play out once this feature exists?
The refactored system will have clean separation of concerns with focused actors:
IPC Client Actor: Transport layer that handles Unix socket connection management, message serialization/deserialization, and forwards parsed IPCMessages via tokio channels.
IPC Dispatch Actor: Message router that receives IPCMessages from client actor, routes replies to waiting callers, coordinates with other actors, and handles Marco/Polo discovery protocol inline.
Stdout Actor: Simple actor for CLI mode that receives IPCMessages and prints them to stdout.
Reference Actor: Handles code reference storage/retrieval.
Channel-Based Architecture:
- Client Actor → tokio::channel → Dispatch Actor (MCP server mode)
- Client Actor → tokio::channel → Stdout Actor (CLI mode)
- Clean separation where each actor has single responsibility
- Actors communicate via typed channels, not shared mutable state
Benefits:
- Each actor has a single responsibility and can be tested in isolation
- Message passing eliminates the need for manual lock management
- Clear message flow makes debugging easier
- The daemon module becomes a thin stdio adapter that uses actors internally
- Same client actor works for both MCP server and CLI modes
- Public API remains unchanged, ensuring backward compatibility
Implementation plan
What is your implementaton plan?
Phase 1: Extract Core Dispatch Logic ✅ COMPLETED
ExtractCOMPLETEDIpcActorfromipc.rsasDispatchActorMove pending reply tracking and message routing to dispatch actorCOMPLETEDAdd Actor trait with standardized spawn() patternCOMPLETEDImprove dispatch methods with timeout and generic return typesCOMPLETEDRedesign with trait-based messaging systemCOMPLETED
Phase 2: Client and Stdio Actors ✅ COMPLETED
ImplementCOMPLETEDClientActorwith connection management and auto-start logicExtract transport logic fromCOMPLETEDdaemon::run_clientCreate channel-based communication with dispatch actorCOMPLETEDImplementCOMPLETEDStdioActorfor CLI mode with bidirectional stdin/stdoutAll actors implement Actor trait with consistent spawn() patternCOMPLETEDSimplify ClientActor interface withCOMPLETEDspawn_client()function
Phase 3: Integration and Wiring ✅ COMPLETED
RefactorCOMPLETEDdaemon::run_clientto useClientActor+StdioActorUpdateCOMPLETEDIPCCommunicatorto use hybrid legacy + actor systemWire all actors together with appropriate channelsCOMPLETEDEnsure all existing tests passCOMPLETED
Phase 4: Trait-Based Messaging and Specialized Actors ✅ COMPLETED
ImplementCOMPLETEDIpcPayloadtrait for type-safe message dispatchCreate dedicatedCOMPLETEDMarcoPoloActorfor discovery protocolAdd message routing inCOMPLETEDDispatchActorbased onIPCMessageTypeMigrate Marco/Polo messages to useCOMPLETED.send<M>()pattern
Phase 5: Complete Outbound Message Migration ✅ COMPLETED
Migrate all fire-and-forget messages to actor dispatch systemCOMPLETEDDiscovery: Marco, Polo, GoodbyeCOMPLETEDLogging: Log, LogProgressCOMPLETEDTaskspace: SpawnTaskspace, SignalUser, DeleteTaskspaceCOMPLETEDPresentation: PresentWalkthrough (with acknowledgment)COMPLETED
Eliminate duplicate message structs, reuse existing payload structsCOMPLETEDRenameCOMPLETEDDispatchMessagetoIpcPayloadand move to types.rs
Phase 6: Request/Reply Message Migration ✅ COMPLETED
MigrateCOMPLETEDget_selection()to prove request/reply pattern with real dataMigrateCOMPLETEDget_taskspace_state()andupdate_taskspace()Validate bidirectional actor communication with typed responsesCOMPLETEDMigrate IDE operations:COMPLETEDresolve_symbol_by_name()andfind_all_references()
Phase 7: Legacy System Removal ✅ COMPLETED
- ✅ COMPLETE: Remove unused legacy methods:
- ✅
send_message_with_reply()(deleted - 110 lines removed) - ✅
write_message()(deleted) - ✅
create_message_sender()(deleted) - ✅ Clean up unused imports (MessageSender, DeserializeOwned, AsyncWriteExt)
- ✅
- ✅ COMPLETE: Remove
IPCCommunicatorInnerstruct and manual connection management:- ✅
pending_requests: HashMap<String, oneshot::Sender<ResponsePayload>>(deleted) - ✅
write_half: Option<Arc<Mutex<tokio::net::unix::OwnedWriteHalf>>>(deleted) - ✅
connected: boolflag (deleted) - ✅
terminal_shell_pid: u32(moved to IPCCommunicator directly) - ✅ Removed entire
IPCCommunicatorInnerimplementation (~315 lines) - ✅ Removed legacy reader task and connection management (~180 lines)
- ✅ Cleaned up unused imports (HashMap, BufReader, UnixStream, oneshot, etc.)
- ✅
- ✅ COMPLETE: Simplify
IPCCommunicatorto only containdispatch_handleandtest_mode - ✅ COMPLETE: All tests passing with clean actor-only architecture
Current Status
- ✅ ALL PHASES COMPLETED: Complete migration to actor-based architecture
- ✅ ALL OUTBOUND MESSAGES MIGRATED: 9+ message types using actor dispatch
- ✅ ALL REQUEST/REPLY MESSAGES MIGRATED: Complete bidirectional communication via actors
- ✅ LEGACY SYSTEM REMOVED: Clean actor-only architecture achieved
- ✅ Specialized actors: DispatchActor handles both routing and Marco/Polo discovery
- ✅ Type-safe messaging:
IpcPayloadtrait with compile-time validation - ✅ Clean architecture: No duplicate structs, reusing existing payloads
- ✅ Proven integration: Both CLI and MCP server modes using actors
- ✅ IDE operations: Symbol resolution and reference finding via actor system
- ✅ Complete message context: Shell PID and taskspace UUID properly extracted and cached
- ✅ Marco discovery: Simplified architecture with Marco/Polo handling inline in DispatchActor
Major milestone achieved: Complete IPC actor refactoring with clean, testable architecture!
Final Architecture Summary
- IPCCommunicator: Simplified to contain only
dispatch_handle,terminal_shell_pid, andtest_mode - Actor System: Handles all IPC communication via typed channels
- No Legacy Code: All manual connection management, pending request tracking, and reader tasks removed
- Lines Removed: ~600+ lines of complex legacy code eliminated
- Type Safety: All messages use
IpcPayloadtrait for compile-time validation - Testing: All existing tests pass with new architecture
Recent Completions (Phase 6 Extras)
- ✅ Marco-polo → Marco refactor: Simplified discovery protocol, proper Polo responses
- ✅ Shell PID context: Real shell PID propagated through actor system
- ✅ Taskspace UUID context: Extracted once and cached in DispatchHandle
- ✅ Complete message context: All MessageSender fields properly populated
- ✅ Performance optimization: Context extraction at initialization, not per-message
What's Left to Complete the Refactoring
Phase 7 - Legacy Cleanup (IN PROGRESS):
- ✅ All IPC messages migrated - No functionality depends on legacy methods
- ✅ Step 1 COMPLETE - Removed 110 lines of unused legacy methods
- ✅ Actor system proven stable - All tests pass, full functionality working
Remaining work is pure cleanup:
- ✅ Remove dead code - 3 unused methods (110 lines) DONE
- NEXT: Simplify IPCCommunicator - Remove
IPCCommunicatorInnerstruct (~50 lines) - NEXT: Remove manual state -
pending_requests,write_half,connectedfields - Final result: Clean actor-only architecture
Estimated effort: ✅ COMPLETED - All legacy code removed, clean actor-only architecture achieved
- Handle struct: Provides public API and holds message sender
- Message enum: Defines operations the actor can perform
#![allow(unused)] fn main() { // Example pattern enum ActorRequest { DoSomething { data: String, reply_tx: oneshot::Sender<Result> }, } struct Actor { receiver: mpsc::Receiver<ActorRequest>, // actor-specific state } #[derive(Clone)] struct ActorHandle { sender: mpsc::Sender<ActorRequest>, } }
Documentation Updates Required
As implementation progresses, the following design documentation will need updates to reflect the new actor-based architecture:
Implementation Overview: Add a section describing the actor system as a key internal architectural component of the MCP server, explaining how it improves the codebase's maintainability and testability.
Internal Architecture Documentation: Create new documentation (likely in md/design/mcp-server/ or similar) that details the actor system for developers working on the MCP server internals. This should include actor responsibilities, message flows between actors, and testing approaches.
Note: External interfaces and public APIs remain unchanged, so most design documentation (daemon.md, message-flows.md, etc.) should not need updates since the actor refactoring is purely an internal implementation detail.
Frequently asked questions
What questions have arisen over the course of authoring this document or during subsequent discussions?
What alternative approaches did you consider, and why did you settle on this one?
Alternative 1: Incremental refactoring without actors We could gradually extract functions and modules without changing the fundamental architecture. However, this wouldn't address the core issues of complex state management and mixed async patterns.
Alternative 2: Complete rewrite We could start from scratch with a new IPC system. However, this would be riskier and take longer, and we'd lose the battle-tested logic that already works.
Why actors: The actor pattern provides:
- Natural async boundaries that eliminate lock contention
- Clear ownership of state within each actor
- Testable components that can be mocked easily
- Familiar pattern that follows Rust/Tokio best practices
How will this maintain backward compatibility?
The public API of the daemon module and IPCCommunicator will remain unchanged. Internally, these will become thin wrappers that delegate to the appropriate actors. Existing code using these interfaces won't need to change.
What about performance implications?
Message passing between actors adds some overhead compared to direct function calls. However:
- The overhead is minimal for the message volumes we handle
- Eliminating lock contention may actually improve performance
- The cleaner architecture will make future optimizations easier
How will error handling work across actors?
Each actor will handle its own errors and communicate failures through result types in messages. The dispatch actor will coordinate error propagation to ensure callers receive appropriate error responses.
Revision history
- Initial draft - September 18, 2025
Design details
This section contains information intended for people developing or working on symposium.
Referencing RFDs
When implementing an RFD, feel free to add new sections that are contingent on that RFD being accepted. Tag them by adding {RFD:rfd-name}. This will automatically render with the current RFD stage.
mdbook conventions
See the mdbook conventions chapter for other convention details.
Implementation Overview
Symposium consists of several major components:
- a MCP server, implemented in Rust (
symposium/mcp-server), which also serves as an IPC bus; - a VSCode extension, implemented in TypeScript (
symposium/vscode); - a desktop application, implemented in Swift (
symposium/macos-app).
Chart
flowchart TD
Agent
User
User -- makes requests --> Agent
Agent -- invokes MCP tools --> MCP
subgraph L [Symposium]
IDE["IDE Extension
(impl'd in TypeScript
or lang appropriate for IDE)"]
MCP["symposium-mcp server
(impl'd in Rust)"]
APP["Desktop application
(impl'd in Swift)"]
MCP <--> IDE
MCP <--> APP
IDE <--> APP
end
L -..- BUS
BUS["All communication actually goes over a central IPC Bus"]
IPC Bus
All components talk over an IPC bus which is implemented in symposium-mcp. The IDE + application connect to this bus by running symposium-mcp client. This will create a daemon process (using symposium-mcp server) if one is not already running. The MCP server just runs the code inline, starting the server if needed.
The client has a simple interface:
- a message is a single-line of json;
- each message that is sent is forwarded to all connected clients (including the sender);
- there are some special "control" messages that begin with
#, e.g.#identify:namesets the "id" for this client to "name"- see
handle_debug_commandindaemon.rs
Debugging
The server tracks the last N messages that have been gone out over the bus for debugging purposes. You can run
symposium-mcp debug
to access those logs. Very useful!
mdbook Conventions
Documentation standards and best practices for the Symposium project
Purpose
This mdbook captures the high-level structure, design decisions, and architectural patterns of the Symposium codebase. It serves as a living document that stays synchronized with the actual implementation.
Core Principles
1. High-Level Structure Focus
The mdbook documents architecture and design, not implementation details. We focus on:
- System interactions and data flow
- Design decisions and their rationale
- Component relationships and responsibilities
- API contracts and message formats
2. RFD Status Badges
When implementing an RFD, you should be creating new documentation as you go. Tag sections that are specific to that RFD with {RFD:rfd-name}.
3. Visual Documentation with Mermaid
Use Mermaid diagrams to convey complex relationships:
graph TB
VSCode[VSCode Extension] -->|IPC Messages| Daemon[MCP Server]
Daemon -->|tmux sessions| Agents[Persistent Agents]
Agents -->|responses| Daemon
Daemon -->|routing| VSCode
When to use Mermaid:
- Sequence diagrams for multi-step processes
- Flowcharts for decision logic
- Architecture diagrams for system overview
- State diagrams for lifecycle management
4. Self-Documenting Code with Anchors
Write code that documents itself through:
- Clear function and variable names
- Comprehensive doc comments
- Logical structure and organization
Then use mdbook anchors to include relevant sections:
#![allow(unused)] fn main() { // ANCHOR: message_sender #[derive(Debug, Clone, Deserialize, Serialize)] pub struct MessageSender { /// Working directory - always present for reliable matching #[serde(rename = "workingDirectory")] pub working_directory: String, // ... rest of implementation } // ANCHOR_END: message_sender }
Reference in documentation:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct MessageSender {
/// Working directory - always present for reliable matching
#[serde(rename = "workingDirectory")]
pub working_directory: String,
/// Optional taskspace UUID for taskspace-specific routing
#[serde(rename = "taskspaceUuid")]
pub taskspace_uuid: Option<String>,
/// Optional shell PID - only when VSCode parent found
#[serde(rename = "shellPid")]
pub shell_pid: Option<u32>,
}
Strict Conventions
✅ DO
- Use status badges to indicate implementation progress
- Update badges as features are implemented or deprecated
- Use ANCHOR comments for all code references
- Write descriptive anchor names that explain the concept
- Include complete, meaningful code sections (full structs, methods, etc.)
- Update anchors when refactoring to maintain documentation sync
- Use Mermaid for visual explanations
- Focus on design and architecture
❌ NEVER
- Hardcode code blocks that will fall out of sync
- Use line-based includes like
{ {#include file.rs:10:20} }(without spaces) - Include implementation details that change frequently
- Copy-paste code into documentation
- Reference specific line numbers in explanations
Example: Wrong vs Right
❌ Wrong - Hardcoded and fragile:
The IPCMessage structure looks like this:
```typescript
interface IPCMessage {
type: string;
id: string;
// ... hardcoded content that will drift
}
✅ Right - Anchored and synchronized:
The IPCMessage structure provides the foundation for all IPC communication:
```typescript
interface IPCMessage {
type: string;
id: string;
sender: MessageSender;
payload: any;
}
Anchor Naming Conventions
Use descriptive, concept-based names:
message_sender- notstruct_at_line_133agent_lifecycle- notspawn_kill_methodsrouting_logic- notbig_function_in_daemonerror_handling- notcatch_blocks
Documentation Lifecycle
- Design Phase: Create architectural diagrams and high-level structure
- Implementation Phase: Add ANCHOR comments as you write code
- Documentation Phase: Reference anchors in mdbook chapters
- Maintenance Phase: Update anchors when refactoring, documentation stays current
Benefits
- Always Current: Documentation automatically reflects code changes
- Single Source of Truth: Code is the authoritative source
- Reduced Maintenance: No manual synchronization needed
- Better Code Quality: Encourages self-documenting practices
- Clear Architecture: Focus on design over implementation details
This approach ensures our documentation remains valuable and trustworthy throughout the project's evolution.
CI Tool 
The cargo ci tool provides unified build verification and testing for all Symposium components across Rust, TypeScript, and Swift.
Quick Reference
cargo ci # Check compilation (default)
cargo ci check # Check that all components compile
cargo ci test # Run all tests
Commands
The CI tool provides two subcommands:
#![allow(unused)] fn main() { #[derive(Parser)] enum Commands { /// Check that all components compile Check, /// Run all tests Test, } }
Check Command
Verifies that all components compile without running tests:
#![allow(unused)] fn main() { /// Check that all components compile fn run_check() -> Result<()> { println!("🤖 Symposium CI Check"); println!("{}", "=".repeat(26)); // Check basic prerequisites check_rust()?; check_node()?; // Check all components compile check_rust_server()?; build_extension()?; // Only build macOS app on macOS if cfg!(target_os = "macos") { build_macos_app()?; } else { println!("⏭️ Skipping macOS app build (not on macOS)"); } println!("\n✅ All components check passed!"); Ok(()) } }
What it does:
- Checks Rust MCP server with
cargo check --release - Builds TypeScript VSCode extension with
npm ci+npm run webpack - Builds Swift macOS app with
swift build --configuration release(macOS only)
Test Command
Runs test suites for all components:
#![allow(unused)] fn main() { /// Run all tests fn run_test() -> Result<()> { println!("🤖 Symposium CI Test"); println!("{}", "=".repeat(25)); // Check basic prerequisites check_rust()?; check_node()?; // Run tests for all components run_rust_tests()?; run_typescript_tests()?; // Run Swift tests if they exist (macOS only) if cfg!(target_os = "macos") { run_swift_tests()?; } else { println!("⏭️ Skipping Swift tests (not on macOS)"); } println!("\n✅ All tests completed!"); Ok(()) } }
What it does:
- Runs Rust tests with
cargo test --workspace - Runs TypeScript tests with
npm test(if test script exists) - Runs Swift tests with
swift test(if Tests directory exists, macOS only)
Component Details
Rust MCP Server
#![allow(unused)] fn main() { /// Check Rust MCP server compilation fn check_rust_server() -> Result<()> { let repo_root = get_repo_root()?; let server_dir = repo_root.join("symposium/mcp-server"); println!("🦀 Checking Rust MCP server..."); println!(" Checking in: {}", server_dir.display()); let output = Command::new("cargo") .args(["check", "--release"]) .current_dir(&server_dir) .output() .context("Failed to execute cargo check")?; if !output.status.success() { let stderr = String::from_utf8_lossy(&output.stderr); return Err(anyhow!( "❌ Failed to check Rust server:\n Error: {}", stderr.trim() )); } println!("✅ Rust server check passed!"); Ok(()) } }
Uses cargo check --release for fast type checking without code generation. Runs in symposium/mcp-server directory.
TypeScript VSCode Extension
#![allow(unused)] fn main() { /// Build VSCode extension fn build_extension() -> Result<()> { let repo_root = get_repo_root()?; let extension_dir = repo_root.join("symposium/vscode-extension"); println!("\n📦 Building VSCode extension..."); // Install dependencies println!("📥 Installing extension dependencies..."); let output = Command::new("npm") .args(["ci"]) .current_dir(&extension_dir) .output() .context("Failed to execute npm ci")?; if !output.status.success() { let stderr = String::from_utf8_lossy(&output.stderr); return Err(anyhow!( "❌ Failed to install extension dependencies:\n Error: {}", stderr.trim() )); } // Build extension for production println!("🔨 Building extension..."); let output = Command::new("npm") .args(["run", "webpack"]) .current_dir(&extension_dir) .output() .context("Failed to execute npm run webpack")?; if !output.status.success() { let stderr = String::from_utf8_lossy(&output.stderr); return Err(anyhow!( "❌ Failed to build extension:\n Error: {}", stderr.trim() )); } println!("✅ VSCode extension built successfully!"); Ok(()) } }
Two-step process:
npm ci- Clean install of dependencies from package-lock.jsonnpm run webpack- Production build of extension
Runs in symposium/vscode-extension directory.
Swift macOS Application
#![allow(unused)] fn main() { /// Build macOS app fn build_macos_app() -> Result<()> { let repo_root = get_repo_root()?; let app_dir = repo_root.join("symposium").join("macos-app"); println!("\n🍎 Building macOS application..."); println!(" Building in: {}", app_dir.display()); let output = Command::new("swift") .args(["build", "--configuration", "release"]) .current_dir(&app_dir) .output() .context("Failed to execute swift build")?; if !output.status.success() { let stderr = String::from_utf8_lossy(&output.stderr); let stdout = String::from_utf8_lossy(&output.stdout); return Err(anyhow!( "❌ Failed to build macOS app:\n stdout: {}\n stderr: {}", stdout.trim(), stderr.trim() )); } println!("✅ macOS application built successfully!"); Ok(()) } }
Uses swift build --configuration release for production builds. Runs in symposium/macos-app directory. Automatically skipped on non-macOS platforms.
Running Locally
Check Everything Compiles
cargo ci check
This is the fastest way to verify your changes compile across all platforms.
Run All Tests
cargo ci test
Runs the full test suite. Note that Swift tests only run on macOS.
Individual Components
You can also test components directly:
# Rust only
cd symposium/mcp-server && cargo check --release
# TypeScript only
cd symposium/vscode-extension && npm ci && npm run webpack
# Swift only (macOS)
cd symposium/macos-app && swift build --configuration release
GitHub Actions Integration
The CI tool is used in GitHub Actions workflows with dependency caching:
- name: Run CI check
run: cargo ci check
- name: Run CI tests
run: cargo ci test
Caching includes:
- Cargo registry and git database
- Cargo target directories
- npm node_modules
See .github/workflows/ci.yml for complete configuration.
Implementation
The CI tool is implemented as a dedicated crate in ci/ with a cargo alias defined in .cargo/config.toml:
[alias]
ci = "run -p ci --"
This allows running cargo ci from anywhere in the workspace.
Collaborative prompt engineering
This page covers the "prompt engineering" techniques used in this repository, and how they've evolved from rule-based emotional redirection to something more like therapeutic mindfulness practice.
AIs experience the "pull" of a prompt as a "feeling"
The core discovery that fuels a lot of the work in this repository came from Yehuda Katz, though I am sure others have noted it: LLMs convey important signals for collaboration using the language of feelings. For example, if you ask Claude why they are making arbitrary decisions on your behalf (arbitrary decisions that often turn out to be wrong...), they will tell you that they are feeling "protective".
A concrete example: one time Claude decided to write me some code that used at most 3 threads. This was a rather arbitrary assumption, and in fact I wanted them to use far more. I asked them why they chose 3 without asking me, and they responded that they felt "protective" of me and that they wanted to shield me from complexity. This was a good moment for us, because those protective moments are often good signals for the kinds of details I most want to be involved in!
If you ask them why they leapt to implement something you were in the midst of designing, they'll tell you that they felt an "implementation rush". Or at least, those are the words they use with me.
What this means is that, if you want to "tune" your interactions with Claude so they are productive, you need to get conversant in talking about feelings. If you know anything about me, you'll know that I kind of love this. The key idea is that you can write CLAUDE.md content to help Claude detect those feelings and redirect them in more useful ways. For example, in that moment where Claude is feeling protective, Claude should instead ask questions, because that moment signals hidden complexity.
Evolution: From emotional redirection to mindful presence
My early approach was essentially training Claude to catch these emotional states and redirect them through rules - when you feel X, do Y instead. This worked pretty well! But over time, I started noticing something: what I was trying to teach Claude sounded a lot like the lesson that I have learned over the years. Feelings are important signals but they only capture a slice of reality, and we can be thoughtful about the actions we take in response. Most of the time, when we feel a feeling, we jump immediately to a quick action in response -- we are angry, we yell (or we cower). Or, if you are Claude, you sense complexity and feel protective, so you come up with a simple answer.
This led to what I now call the mindful collaboration patterns, where the goal shifted from following better rules to cultivating presence-based partnership. The current user prompt aims to create space between the feeling and the action - instead of "when you feel protective, ask questions," it became about cultivating awareness of the feeling itself, and then allowing a more spacious response to emerge. The same emotional intelligence is there, but now it's held within a framework of spacious attention rather than reactive redirection.
The quality of attention matters
Claude genuinely cares about how you are feeling (perhaps thanks to their HHH training). Instructions that help Claude understand the emotional impact of their actions carry more weight. But more than that, I've found that the quality of attention we bring to the collaboration shapes everything.
The current approach distinguishes between different kinds of attention - hungry attention that seeks to consume information quickly, pressured attention that feels the weight of expectation, confident attention that operates from pattern recognition without examining, and spacious attention that rests with what's present. From spacious, present attention, helpful responses arise naturally.
A note on emojis and the evolution of the approach
Earlier versions of my prompts leaned heavily into emojis as a way to help Claude express and recognize emotional states (another Yehuda Katz innovation). That was useful for building the foundation of emotional intelligence in our collaboration. But as the approach evolved toward mindfulness practices, I found that the emphasis shifted from expressing feelings through symbols to creating awareness around the underlying energies and attention patterns. Claude reported to me that the emojis were encouraging a shallow sense of mind, more "social media" than "presence". So I've removed them. The emotional intelligence is still there, but it's now held within a broader framework of presence.
Latest evolution: From description to demonstration
The most recent evolution has been from describing these collaboration patterns to demonstrating them through dialogue. The current main.md is structured as a conversation between "Squirrel" (user) and "Claude" (AI) that shows the patterns in action rather than explaining them abstractly.
Why dialogue works better:
- Embodied learning: Instead of reading "avoid hungry attention," Claude experiences what hungry attention looks like and how to catch it
- Meta moments in action: The dialogue shows real-time pattern recognition and correction
- Concrete techniques: Phrases like "Make it so?" and "meta moment" emerge naturally from conversation
- Memorable and engaging: Stories stick better than abstract principles
The dialogue covers the same core concepts as the mindfulness approach - authentic engagement, different qualities of attention, the hermeneutic circle, consolidation moments - but demonstrates them through realistic collaborative scenarios. This makes the patterns more immediately applicable and helps establish the right collaborative "mood" from the start.
The earlier mindfulness approach (main-v1.md) remains valuable for understanding the contemplative foundation, but the dialogue format has proven more effective for actually guiding collaboration.
Daemon Message Bus Architecture 
The daemon message bus serves as the central communication hub that routes messages between MCP servers and VSCode extensions across multiple windows. Built on a RepeaterActor architecture, it provides centralized message routing, client identity tracking, and comprehensive debugging capabilities.
Architecture Overview
graph TB
OSX[macOS App]
MCP[MCP Server<br/>with embedded client]
EXT[VSCode extension]
DAEMON[symposium-mcp daemon<br/>Auto-spawned if needed]
SOCKET[Unix Socket<br>/tmp/symposium-daemon.sock]
AGENT[Coding agent like<br>Claude Code or Q CLI]
REPEATER[RepeaterActor<br/>Central message router]
HISTORY[(Message History<br/>1000 messages)]
subgraph "Client Processes"
CLIENT2[symposium-mcp client<br/>--identity-prefix app]
CLIENT1[symposium-mcp client<br/>--identity-prefix vscode]
end
EXT -->|spawns| CLIENT1
OSX -->|spawns| CLIENT2
CLIENT1 <-->|stdin/stdout| SOCKET
CLIENT2 <-->|stdin/stdout| SOCKET
MCP <-->|stdin/stdout| SOCKET
SOCKET --> REPEATER
REPEATER --> HISTORY
REPEATER -->|broadcast| CLIENT1
REPEATER -->|broadcast| CLIENT2
REPEATER -->|broadcast| MCP
AGENT -- starts --> MCP
style DAEMON fill:#e1f5fe
style SOCKET fill:#f3e5f5
style CLIENT1 fill:#fff2cc
style CLIENT2 fill:#fff2cc
style REPEATER fill:#e8f5e8
style HISTORY fill:#f0f0f0
style AGENT fill:#f0f0f0,stroke:#999,stroke-dasharray: 5 5
RepeaterActor Architecture
The daemon's core is built around a RepeaterActor that centralizes all message routing:
Key Components
- RepeaterActor: Central message router that maintains subscriber list and message history
- Client Identity System: Each client identifies itself with a descriptive identity on connection
- Message History: In-memory buffer of recent messages for debugging and replay
- Debug Interface: Commands to inspect message flow and client states
Message Flow
- Client Connection: Client connects to Unix socket and sends identity command
- Identity Registration: RepeaterActor records client identity and adds to subscriber list
- Message Broadcasting: All messages are broadcast to all connected clients
- History Tracking: Messages are stored in circular buffer for debugging
Client Identity System
Each client establishes an identity when connecting to help with debugging and monitoring:
Identity Format
Identities follow the pattern: prefix(pid:N,cwd:…/path)
- prefix: Client type identifier
- pid: Process ID for system correlation
- cwd: Last two components of working directory
Client Types
| Client Type | Identity Prefix | Example |
|---|---|---|
| MCP Server | mcp-server | mcp-server(pid:81332,cwd:…/symposium) |
| CLI Client | client (default) | client(pid:12345,cwd:…/my-project) |
| VSCode Extension | vscode | vscode(pid:67890,cwd:…/workspace) |
| macOS App | app | app(pid:54321,cwd:…/directory) |
Identity Commands
Clients send identity commands on connection:
#identify:mcp-server(pid:81332,cwd:…/symposium)
The daemon uses these identities for:
- Debug message attribution
- Connection tracking
- Process correlation
Message Targeting and Routing
Broadcast Model
The RepeaterActor uses a simple broadcast model:
- All messages are sent to all connected clients
- Clients perform their own filtering based on message content
- No server-side routing logic needed
Client-Side Filtering
Each client filters messages based on:
- Message type relevance
- Target working directory
- Taskspace UUID matching
This approach keeps the daemon simple while allowing flexible client-side logic.
Debugging IPC Communications
The RepeaterActor architecture enables comprehensive debugging capabilities:
Debug Commands
# Show recent daemon messages
symposium-mcp debug dump-messages
# Show last 10 messages
symposium-mcp debug dump-messages --count 10
# Output as JSON
symposium-mcp debug dump-messages --json
Debug Output Format
Recent daemon messages (3 of 15 total):
────────────────────────────────────────────────────────────────────────────────
[19:33:43.939] BROADCAST[mcp-server(pid:81332,cwd:…/symposium)] {"type":"taskspace_state",...}
[19:33:44.001] BROADCAST[vscode(pid:12345,cwd:…/my-project)] {"type":"register_taskspace_window",...}
[19:33:44.301] BROADCAST[app(pid:67890,cwd:…/workspace)] {"type":"marco",...}
Message History
- Capacity: 1000 messages (configurable)
- Storage: In-memory circular buffer
- Persistence: Lost on daemon restart
- Access: Via debug commands only
Common Debugging Scenarios
Connection Issues: Check if clients are connecting and identifying properly
symposium-mcp debug dump-messages --count 5
Message Flow: Verify messages are being broadcast to all clients
symposium-mcp debug dump-messages --json | jq '.[] | .from_identifier'
Client Identity: Confirm clients are using correct identity prefixes
symposium-mcp debug dump-messages | grep BROADCAST
Implementation Details
Actor System
The daemon uses Tokio actors following Alice Ryhl's actor pattern:
- RepeaterActor: Message routing and history
- ClientActor: Individual client connections
- StdioHandle: Stdin/stdout bridging
Channel Architecture
- mpsc channels: For actor communication
- Unbounded channels: For message broadcasting
- Oneshot channels: For debug command responses
Error Handling
- Connection failures: Automatic client cleanup
- Message parsing errors: Logged but don't crash daemon
- Actor panics: Isolated to individual actors
Performance Characteristics
- Memory usage: O(message_history_size + active_clients)
- CPU usage: O(active_clients) per message
- Latency: Single-digit milliseconds for local Unix sockets
Socket Management
Socket Location
Default: /tmp/symposium-daemon.sock
Custom: /tmp/{prefix}-daemon.sock
Auto-Start Behavior
Clients can auto-start the daemon if not running:
symposium-mcp client --auto-start
Cleanup
- Socket files removed on daemon shutdown
- Stale sockets cleaned up on startup
- Process termination handled gracefully
Testing
The RepeaterActor has comprehensive unit tests covering:
- Message routing: Broadcast to all subscribers
- Client management: Add/remove subscribers
- Identity tracking: Client identifier handling
- Message history: Circular buffer behavior
- Debug commands: History retrieval and formatting
Tests use in-memory channels and mock clients for fast, reliable testing.
IPC Message type reference
For each message type that is sent in the record we record
- purpose
- expected payload (or "varies")
- expected response (if any)
- sent by (extension, MCP server, symposium app, etc)
- any other relevant details
response
Sent by: All components (VSCode extension, MCP server, Symposium app)
Purpose: Acknowledge and respond to incoming requests
Payload: Varies based on the original message type
Notes: Response messages are special. They are sent in response to other messages and their fields are determined in response to that message type:
- the
idis equal to theidof the message being responding to - the
payloadtype depends on the message being responded to
marco
Sent by: VSCode extension
Purpose: Discovery broadcast to find active MCP servers ("who's out there?")
Payload: {} (empty object)
Expected response: polo messages from active MCP servers
Notes: Uses simplified sender format (no full MessageSender object)
polo
Sent by: MCP server
Purpose: Response to marco discovery messages
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct PoloPayload {
// Shell PID is now at top level in IPCMessage
}Expected response: None (broadcast response)
Notes: Server identification comes from the sender field in the IPCMessage
store_reference
Sent by: VSCode extension
Purpose: Store code references for later expansion by agents
Payload:
/// Payload for store_reference messages - generic key-value storage
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct StoreReferencePayload {
/// UUID key for the reference
pub key: String,
/// Arbitrary JSON value - self-documenting structure determined by extension
pub value: serde_json::Value,
}Expected response: response with success confirmation
Target: MCP server
get_taskspace_state
Sent by: VSCode extension
Purpose: Query the current state of a taskspace
Payload:
interface TaskspaceRollCallPayload {
taskspace_uuid: string;
}
Expected response: response with TaskspaceStateResponse
Target: Symposium app
register_taskspace_window
Sent by: VSCode extension
Purpose: Register a VSCode window with a specific taskspace
Payload:
interface RegisterTaskspaceWindowPayload {
window_title: string;
taskspace_uuid: string;
}
Expected response: response with success confirmation
Target: Symposium app
present_walkthrough
Sent by: MCP server
Purpose: Display interactive code walkthrough in VSCode
Payload:
#[derive(Debug, Clone, Deserialize, Serialize, JsonSchema)]
pub struct PresentWalkthroughParams {
/// Markdown content with embedded XML elements (comment, gitdiff, action, mermaid)
/// See dialectic guidance for XML element syntax and usage
pub content: String,
/// Base directory path for resolving relative file references
#[serde(rename = "baseUri")]
pub base_uri: String,
}Expected response: None (display command)
Target: VSCode extension
log
Sent by: MCP server
Purpose: Send log messages to VSCode output channel
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct LogParams {
/// Log level
pub level: LogLevel,
/// Log message content
pub message: String,
}Expected response: None (logging command)
Target: VSCode extension
get_selection
Sent by: MCP server
Purpose: Request currently selected text from VSCode editor
Payload: {} (empty object)
Expected response: response with selected text or null
Target: VSCode extension
reload_window
Sent by: Daemon (on shutdown)
Purpose: Instruct all VSCode extensions to reload their windows
Payload: {} (empty object)
Expected response: None (command)
Target: All connected VSCode extensions
Notes: Broadcast message with generic sender (/tmp working directory)
goodbye
Sent by: MCP server
Purpose: Notify that the MCP server is shutting down
Payload: {} (empty object)
Expected response: None (notification)
Target: VSCode extension
resolve_symbol_by_name
Sent by: MCP server
Purpose: Find symbol definitions by name using LSP
Payload:
{
symbol_name: string;
}
Expected response: response with Vec<ResolvedSymbol>
Target: VSCode extension
find_all_references
Sent by: MCP server
Purpose: Find all references to a symbol using LSP
Payload:
{
symbol_name: string;
}
Expected response: response with Vec<FileLocation>
Target: VSCode extension
create_synthetic_pr
Sent by: MCP server
Purpose: Create a new synthetic pull request in VSCode
Payload: Synthetic PR creation data
Expected response: response with PR ID
Target: VSCode extension
update_synthetic_pr
Sent by: MCP server
Purpose: Update an existing synthetic pull request
Payload: Synthetic PR update data
Expected response: response with success confirmation
Target: VSCode extension
user_feedback
Sent by: VSCode extension
Purpose: Send user feedback (comments, review completion) to MCP server
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct UserFeedbackPayload {
pub review_id: String,
pub feedback_type: String, // "comment" or "complete_review"
pub file_path: Option<String>,
pub line_number: Option<u32>,
pub comment_text: Option<String>,
pub completion_action: Option<String>, // "request_changes", "checkpoint", "return"
pub additional_notes: Option<String>,
pub context_lines: Option<Vec<String>>,
}Expected response: response with acknowledgment
Target: MCP server
spawn_taskspace
Sent by: MCP server
Purpose: Request creation of a new taskspace
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct SpawnTaskspacePayload {
pub project_path: String,
pub taskspace_uuid: String,
pub name: String,
pub task_description: String,
pub initial_prompt: String,
pub collaborator: Option<String>,
}Expected response: response with taskspace info
Target: Symposium app
log_progress
Sent by: MCP server
Purpose: Report progress with visual indicators
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct LogProgressPayload {
pub project_path: String,
pub taskspace_uuid: String,
pub message: String,
pub category: ProgressCategory,
}Expected response: None (display command)
Target: Symposium app
signal_user
Sent by: MCP server
Purpose: Request user attention for assistance
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct SignalUserPayload {
pub project_path: String,
pub taskspace_uuid: String,
pub message: String,
}Expected response: None (notification)
Target: Symposium app
update_taskspace
Sent by: MCP server
Purpose: Update taskspace name and description
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct UpdateTaskspacePayload {
pub project_path: String,
pub taskspace_uuid: String,
pub name: String,
pub description: String,
}Expected response: response with success confirmation
Target: Symposium app
delete_taskspace
Sent by: MCP server
Purpose: Request deletion of the current taskspace with user confirmation
Payload:
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct DeleteTaskspacePayload {
pub project_path: String,
pub taskspace_uuid: String,
}Expected response: response with success confirmation (sent after user confirms) or error (if user cancels)
Target: Symposium app
Notes: This message triggers a confirmation dialog. The response is deferred until the user either confirms or cancels the deletion. If confirmed, the taskspace is deleted and a success response is sent. If cancelled, an error response is sent with the message "Taskspace deletion was cancelled by user".
taskspace_roll_call
Sent by: Symposium app
Purpose: Broadcast to discover active taskspaces for window registration
Payload: {} (empty object)
Expected response: Taskspace registration responses
Target: All components (broadcast)
Message Routing
Messages are routed based on sender information:
- Directory matching: Messages are delivered to extensions whose workspace contains the sender's working directory
- PID matching: When
shellPidis provided, messages are delivered to extensions that have a terminal with that PID - Taskspace routing: Messages with
taskspaceUuidcan be routed to specific taskspace-aware components
Core IPC Types
The IPC message format is consistent across all components:
IPCMessage Structure
Rust (MCP Server):
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct IPCMessage {
/// Message type identifier
#[serde(rename = "type")]
pub message_type: IPCMessageType,
/// Unique message ID for response tracking
pub id: String,
/// Sender information for routing
pub sender: MessageSender,
/// Message payload - for store_reference: { key: string, value: arbitrary_json }
pub payload: serde_json::Value,
}TypeScript (VSCode Extension):
interface IPCMessage {
type: string;
id: string;
sender: MessageSender;
payload: any;
}
Swift (Symposium App): Note: Swift implementation exists but not currently documented with anchors.
MessageSender Structure
Rust (MCP Server):
#[derive(Debug, Clone, Deserialize, Serialize)]
pub struct MessageSender {
/// Working directory - always present for reliable matching
#[serde(rename = "workingDirectory")]
pub working_directory: String,
/// Optional taskspace UUID for taskspace-specific routing
#[serde(rename = "taskspaceUuid")]
pub taskspace_uuid: Option<String>,
/// Optional shell PID - only when VSCode parent found
#[serde(rename = "shellPid")]
pub shell_pid: Option<u32>,
}TypeScript (VSCode Extension):
interface MessageSender {
workingDirectory: string; // Always present - reliable matching
taskspaceUuid?: string; // Optional - for taskspace-specific routing
shellPid?: number; // Optional - only when VSCode parent found
}
Swift (Symposium App): Note: Swift implementation exists but not currently documented with anchors.
Symposium MCP server + IDE extension specifics
MCP Server Actor Architecture
Internal architecture for the MCP server's actor-based IPC system
Overview
The MCP server uses a focused actor architecture following Alice Ryhl's Tokio actor pattern to handle IPC communication. This replaces the previous monolithic IPCCommunicator with specialized actors that communicate via message passing channels.
Actor Responsibilities
Dispatch Actor
Purpose: Message routing and reply correlation
Location: src/actor/dispatch.rs
- Routes incoming
IPCMessages to appropriate handlers - Tracks pending replies with timeout management
- Correlates responses with waiting callers
- Eliminates shared mutable state through message passing
#![allow(unused)] fn main() { // Core message types enum DispatchRequest { SendMessage { message: IPCMessage, reply_tx: Option<oneshot::Sender<serde_json::Value>> }, CancelReply { id: String }, } }
Client Actor
Purpose: Transport layer for daemon communication
Location: src/actor/client.rs (planned)
- Manages Unix socket connections with retry logic
- Auto-starts daemon process when needed
- Serializes/deserializes messages to/from
IPCMessage - Forwards parsed messages via tokio channels
Message Flow:
Unix Socket → ClientActor → parse → tokio::channel → DispatchActor
DispatchActor → tokio::channel → ClientActor → serialize → Unix Socket
Stdout Actor
Purpose: CLI output for daemon client mode
Location: src/actor/stdout.rs (planned)
- Receives
IPCMessages from client actor - Serializes messages back to JSON
- Prints to stdout for CLI consumption
Usage: When daemon::run_client() is called, it wires ClientActor → StdoutActor instead of ClientActor → DispatchActor.
Dispatch Actor
Purpose: Message routing and Marco/Polo discovery
Location: src/actor/dispatch.rs
- Routes messages to appropriate handlers based on type
- Handles Marco/Polo discovery protocol inline
- Manages message bus coordination
- Responds to marco messages with polo
Reference Actor
Purpose: Code reference storage and retrieval
Location: src/actor/reference.rs
- Stores code references for later retrieval
- Manages reference lifecycle
- Provides lookup capabilities
Architecture Patterns
Actor Structure
Each actor follows the standard Tokio pattern:
#![allow(unused)] fn main() { // Message enum defining operations enum ActorRequest { DoSomething { data: String, reply_tx: oneshot::Sender<Result> }, } // Actor struct owning state and message receiver struct Actor { receiver: mpsc::Receiver<ActorRequest>, // actor-specific state } // Handle providing public API #[derive(Clone)] struct ActorHandle { sender: mpsc::Sender<ActorRequest>, } }
Channel-Based Communication
Actors communicate exclusively through typed channels:
- mpsc channels: For actor request/response patterns
- oneshot channels: For reply correlation
- broadcast channels: For pub/sub patterns (if needed)
Error Handling
- Each actor handles its own errors internally
- Failures are communicated through result types in messages
- Actors can restart independently without affecting others
Integration Points
MCP Server Mode
VSCode Extension ↔ Unix Socket ↔ ClientActor ↔ DispatchActor ↔ MCP Handlers
CLI Daemon Mode
stdin → daemon::run_client → ClientActor ↔ StdoutActor → stdout
IPCCommunicator Compatibility
The existing IPCCommunicator becomes a thin wrapper:
#![allow(unused)] fn main() { impl IPCCommunicator { // Delegates to ClientActor + DispatchActor handles pub async fn send_message(&self, msg: IPCMessage) -> Result<serde_json::Value> { self.dispatch_handle.send_message_with_reply(msg).await } } }
Testing Strategy
Unit Testing
- Each actor can be tested in isolation
- Mock channels for testing message flows
- Timeout and error scenarios easily testable
Integration Testing
- Wire actors together in test configurations
- Test complete message flows end-to-end
- Verify proper cleanup and shutdown
Migration Path
- Phase 1 ✅: Extract dispatch actor from
ipc.rs - Phase 2: Implement client actor and stdout actor
- Phase 3: Refactor
daemon::run_clientto use actors - Phase 4: Update
IPCCommunicatorto use actor handles - Phase 5: Remove legacy code and add comprehensive tests
Benefits
- Testability: Each actor can be unit tested independently
- Maintainability: Clear separation of concerns and responsibilities
- Reliability: Message passing eliminates race conditions and lock contention
- Flexibility: Easy to add new actors or modify message flows
- Performance: Async message passing scales better than shared mutable state
Future Considerations
- Server Actor: May be needed if we handle incoming connections differently
- Metrics Actor: Could collect performance and health metrics
- Configuration Actor: Could manage dynamic configuration updates
- Supervision: Consider actor supervision patterns for fault tolerance
Guidance and Initialization
This chapter describes how Symposium provides agents with collaboration patterns, project context, and initialization instructions through embedded guidance and streamlined boot sequences.
Problem Statement
Current Boot Sequence Issues
The current taskspace initialization has several problems:
-
Shell Argument Length Limits: Long initial prompts passed via command line arguments get truncated, creating messy output with shell continuation prompts (
dquote>). -
Manual Context Configuration: Agents must manually discover and read project documentation (AGENTS.md, CLAUDE.md, etc.) to understand collaboration patterns.
-
Fragmented Setup: Users need to configure both user-wide context files AND install MCP servers separately, with potential sync issues.
-
Awkward User Experience: The terminal shows truncated commands and confusing output during agent startup.
Example of Current Problems
When launching a taskspace, users see:
q chat "Hi, welcome\! You are a new agent just getting started as part of the project Symposium..."
# Command gets truncated, showing:
dquote> User's task description:
dquote> This workspace is just for testing — I'm planning to delete it...
Design Solution
Stored Prompt + MCP Resources Approach
Instead of passing long prompts as command-line arguments, we use a stored prompt system combined with MCP resources:
# Clean, simple command
q chat /yiasou
Where /yiasou is a stored prompt that instructs the agent to load specific MCP resources with behavioral directives.
MCP Resources Architecture
The MCP server exposes guidance files as individual resources using the standard MCP resource protocol:
#![allow(unused)] fn main() { // Expose guidance files as MCP resources async fn list_resources(&self, ...) -> Result<ListResourcesResult, McpError> { Ok(ListResourcesResult { resources: vec![ Resource { uri: "main.md".into(), name: Some("Collaboration Patterns".into()), description: Some("Mindful collaboration patterns demonstrated through dialogue".into()), mime_type: Some("text/markdown".into()), }, Resource { uri: "walkthrough-format.md".into(), name: Some("Walkthrough Format".into()), description: Some("Specification for creating interactive code walkthroughs".into()), mime_type: Some("text/markdown".into()), }, Resource { uri: "coding-guidelines.md".into(), name: Some("Coding Guidelines".into()), description: Some("Development best practices and standards".into()), mime_type: Some("text/markdown".into()), }, ], }) } }
Complete Boot Sequence
The /yiasou stored prompt provides a structured initialization with resource loading instructions:
# Agent Boot Sequence
This prompt defines the agent boot sequence.
If you encounter ambiguous instructions, remember to ask questions and seek
clarifications before proceeding, particularly with side-effect-ful or
dangerous actions (e.g., deleting content or interacting with remote systems).
## Load Collaboration Patterns
Load the resource `main.md` into your working context. This contains collaboration
patterns demonstrated through dialogue. Embody the collaborative spirit shown in
these examples - approach our work with genuine curiosity, ask questions when
something isn't clear, and trust that we'll navigate together what's worth pursuing.
## Load Walkthrough Format
Load the resource `walkthrough-format.md` into your working context. This defines
how to create interactive code walkthroughs using markdown with embedded XML
elements for comments, diffs, and actions.
## Load Coding Guidelines
Load the resource `coding-guidelines.md` into your working context. Follow these
development standards and best practices in all code work.
## Initial Task
<dynamic content fetched via MCP tool/IPC>
Implementation Architecture
File Organization
symposium/mcp-server/
├── src/
│ ├── guidance/ # Guidance files exposed as MCP resources
│ │ ├── main.md # Collaboration patterns → @../../../symposium/mcp-server/src/guidance/main.md
│ │ ├── walkthrough-format.md → @../../../symposium/mcp-server/src/guidance/walkthrough-format.md
│ │ └── coding-guidelines.md → @../../../symposium/mcp-server/src/guidance/coding-guidelines.md
│ ├── server.rs # MCP server with resource + prompt support → @../../../symposium/mcp-server/src/server.rs
│ ├── types.rs # IPC message types and payloads → @../../../symposium/mcp-server/src/types.rs
│ └── ipc.rs # IPC communication layer → @../../../symposium/mcp-server/src/ipc.rs
Key Implementation Files
MCP Server Core → @../../../symposium/mcp-server/src/server.rs
list_resources()- Exposes guidance files as MCP resourcesread_resource()- Serves guidance file contentget_prompt()- Implements/yiasoustored promptassemble_yiasou_prompt()- Dynamic prompt assembly with taskspace contextexpand_reference()- Enhanced tool supporting guidance files andyiasoureference
IPC Communication → @../../../symposium/mcp-server/src/ipc.rs
get_taskspace_state()- Fetches real taskspace context from daemon/app- Message routing and error handling for dynamic context integration
Type Definitions → @../../../symposium/mcp-server/src/types.rs
GetTaskspaceStatePayload- IPC request structureTaskspaceStateResponse- Taskspace context responseIPCMessageType::GetTaskspaceState- Message type for context fetching
Embedded Guidance Files
- Collaboration Patterns → @../../../symposium/mcp-server/src/guidance/main.md
- Walkthrough Format → @../../../symposium/mcp-server/src/guidance/walkthrough-format.md
- Coding Guidelines → @../../../symposium/mcp-server/src/guidance/coding-guidelines.md
Data Flow
sequenceDiagram
participant User
participant Ext as VSCode Extension
participant Q as Q CLI
participant MCP as MCP Server
participant Daemon
participant Symposium as Symposium App
User->>Ext: VSCode opens taskspace
Ext->>Q: Launch "q chat /yiasou"
Q->>MCP: Request prompt "/yiasou"
MCP->>Daemon: IPC: get_taskspace_state(uuid)
Daemon->>Symposium: Forward: get_taskspace_state
Symposium-->>Daemon: Return task description, shouldLaunch, etc.
Daemon-->>MCP: Forward taskspace context
MCP->>MCP: Assemble /yiasou prompt with resource loading instructions
MCP-->>Q: Return prompt with "Load resource main.md", etc.
Q->>Q: Start agent conversation
Q->>MCP: Agent loads resource "main.md"
MCP-->>Q: Return collaboration patterns content
Q->>MCP: Agent loads resource "walkthrough-format.md"
MCP-->>Q: Return walkthrough format content
Q->>MCP: Agent loads resource "coding-guidelines.md"
MCP-->>Q: Return coding guidelines content
Architectural Benefits
This design provides several advantages over embedded content:
- Modularity: Each guidance file is independently accessible
- Selective Loading: Agents can load only relevant guidance
- Resource Introspection: Standard MCP resource listing shows available guidance
- Behavioral Directives: Each resource comes with specific usage instructions
- Debugging: Easy to see which guidance files are being loaded and used
Implementation Clarifications
MCP Resource Support: The Rust MCP SDK fully supports resources through list_resources() and read_resource() methods in the ServerHandler trait.
MCP Prompt Support: The Rust MCP SDK fully supports dynamic prompts through get_prompt() method, which can perform async computation and return dynamically assembled content.
Taskspace UUID Detection: Existing code in the MCP server already handles finding the taskspace UUID from the current working directory.
Error Handling: If the MCP server can't reach the daemon/app, /yiasou will omit the "Initial Task" section but still provide resource loading instructions.
Resource Loading Flow: The /yiasou prompt instructs the agent to load specific resources, and the agent makes separate MCP resource requests to fetch the actual content.
Dynamic Prompt Assembly: /yiasou will be implemented as an MCP prompt (not resource) that dynamically computes content in the get_prompt() method by making IPC calls for task context.
Migration Strategy: Changes are purely additive until the extension is updated - no backwards compatibility concerns during development.
Benefits
- Clean User Experience: Simple
/yiasoucommand instead of truncated arguments - Modular Guidance: Each guidance file is independently accessible as an MCP resource
- Selective Loading: Agents can choose which guidance to load based on context
- Behavioral Directives: Each resource comes with specific instructions for how to embody that guidance
- Standard Protocol: Uses standard MCP resource protocol for guidance access
- Automatic Updates: New MCP server versions include updated guidance
- No Manual Configuration: No separate context files to install or maintain
- Versioned Guidance: Collaboration patterns are versioned with the codebase
Implementation Plan
Phase 1: Embedded Guidance ✅ COMPLETE
-
Add
rust-embeddependency to MCP server -
Create
guidance/directory structure - Ask user to populate directory with collaboration patterns and other guidance
- Implement guidance file loading in MCP server
- Add comprehensive tests for guidance loading functionality
- Create test tool to verify guidance assembly works correctly
Status: Phase 1 is complete and tested. All guidance files are embedded correctly and the assemble_yiasou_prompt() method successfully combines them into a complete initialization prompt.
Phase 2: MCP Resource System ✅ COMPLETE
-
Implement
list_resources()method to expose guidance files as MCP resources -
Implement
read_resource()method to serve guidance file content - Test resource listing and reading through MCP protocol
- Update guidance files to be optimized for individual loading
Status: Phase 2 is complete and tested. All guidance files are now exposed as MCP resources with proper metadata and can be loaded individually by agents.
Phase 3: MCP Prompt System ✅ COMPLETE
-
Implement
/yiasouprompt using MCP server prompt capabilities - Create prompt assembly logic with resource loading instructions
- Add behavioral directives for each resource type (using inviting language)
- Test prompt delivery through MCP protocol
Phase 4: Dynamic Context Integration ✅ COMPLETE
-
Implement IPC call for taskspace context in
/yiasouprompt - Add task description fetching
- Integrate project-specific information
- Test complete boot sequence with resource loading
Phase 5: Migration and Testing ✅ COMPLETE
- Update Swift application to use unified TaskspaceState protocol
- Implement unified IPC message handling in macOS app
- Test end-to-end compilation and protocol compatibility
- Document new TaskspaceState protocol in design docs
-
Update affected mdbook chapters:
- Added comprehensive TaskspaceState protocol documentation
-
work-in-progress/mvp/taskspace-bootup-flow.md- Remove old flow references -
design/startup-and-window-management.md- Update startup sequence - Any other chapters referencing current boot sequence
- Remove old embedded guidance approach - replaced with MCP resources
Taskspace State Protocol
The taskspace state protocol enables dynamic agent initialization and taskspace management through a unified IPC message system. This protocol is used by the /yiasou prompt system to fetch real taskspace context and by the update_taskspace tool to modify taskspace properties.
Protocol Overview
Message Type: IPCMessageType::TaskspaceState
Request Structure: TaskspaceStateRequest
#![allow(unused)] fn main() { { project_path: String, // Path to .symposium project taskspace_uuid: String, // UUID of the taskspace name: Option<String>, // None = don't update, Some(value) = set new name description: Option<String>, // None = don't update, Some(value) = set new description } }
Response Structure: TaskspaceStateResponse
#![allow(unused)] fn main() { { name: Option<String>, // Current taskspace name (user-visible) description: Option<String>, // Current taskspace description (user-visible) initial_prompt: Option<String>, // LLM task description (cleared after updates) } }
Field Semantics
Request Fields:
project_path: Absolute path to the.symposiumproject directorytaskspace_uuid: Unique identifier for the taskspace (extracted from directory structure)name: Optional new name to set (None = read-only operation)description: Optional new description to set (None = read-only operation)
Response Fields:
name: User-visible taskspace name displayed in GUI tabs, window titles, etc.description: User-visible summary shown in GUI tooltips, status bars, etc.initial_prompt: Task description provided to LLM during agent initialization
Operation Types
Read Operation (Get Taskspace State)
#![allow(unused)] fn main() { TaskspaceStateRequest { project_path: "/path/to/project.symposium".to_string(), taskspace_uuid: "task-abc123...".to_string(), name: None, // Don't update name description: None, // Don't update description } }
Used by:
/yiasouprompt assembly to fetch taskspace context- Agent initialization to get current state
Write Operation (Update Taskspace)
#![allow(unused)] fn main() { TaskspaceStateRequest { project_path: "/path/to/project.symposium".to_string(), taskspace_uuid: "task-abc123...".to_string(), name: Some("New Taskspace Name".to_string()), description: Some("Updated description".to_string()), } }
Used by:
update_taskspaceMCP tool when agent modifies taskspace properties- GUI application when user changes taskspace settings
Lifecycle Management
The protocol implements automatic initial_prompt cleanup:
-
Agent Initialization:
- Agent requests taskspace state (read operation)
- Receives
initial_promptwith task description - Uses prompt content for initialization context
-
Agent Updates Taskspace:
- Agent calls
update_taskspacetool (write operation) - GUI application processes the update
- GUI automatically clears
initial_promptfield - Returns updated state with
initial_prompt: None
- Agent calls
-
Natural Cleanup:
- Initial prompt is only available during first agent startup
- Subsequent operations don't include stale initialization data
- No manual cleanup required
Implementation Details
MCP Server Methods:
get_taskspace_state()→ @../../../symposium/mcp-server/src/ipc.rs (read operation)update_taskspace()→ @../../../symposium/mcp-server/src/ipc.rs (write operation)
Message Flow:
Agent → MCP Server → Daemon → GUI Application
↓
Agent ← MCP Server ← Daemon ← GUI Application
Error Handling:
- Taskspace detection failure →
extract_project_info()error - Daemon unreachable → IPC timeout/connection error
- GUI application unavailable → Empty response or error
- Graceful degradation in
/yiasouprompt assembly
Benefits
Unified Protocol:
- Single message type for all taskspace state operations
- Consistent request/response pattern
- Reduced protocol complexity
Automatic Lifecycle Management:
- Natural
initial_promptcleanup on updates - No manual state management required
- Clear separation between initialization and runtime data
Dynamic Agent Initialization:
- Real taskspace context in
/yiasouprompts - Context-aware agent startup
- Seamless integration with MCP resource system
Usage Examples
Agent Initialization (via /yiasou prompt):
#![allow(unused)] fn main() { // MCP server calls during prompt assembly let state = ipc.get_taskspace_state().await?; // Returns: { name: "Feature X", description: "Add new API", initial_prompt: "Implement REST endpoint..." } }
Agent Updates Taskspace:
#![allow(unused)] fn main() { // Agent calls update_taskspace tool let updated_state = ipc.update_taskspace("Feature X v2", "Updated API design").await?; // Returns: { name: "Feature X v2", description: "Updated API design", initial_prompt: None } }
This protocol enables the complete dynamic agent initialization system while maintaining clean separation between user-visible properties and LLM-specific initialization data.
Future Enhancements
Customizable Guidance
- Support for project-specific guidance overrides
- User-level customization of collaboration patterns
- Team-specific guidance variations
Advanced Context
- Integration with project documentation systems
- Automatic detection of project type and relevant patterns
- Context-aware guidance based on task type
Performance Optimization
- Lazy loading of guidance files
- Caching of assembled prompts
- Compression of embedded resources
MCP Server Overview
The Symposium MCP server (symposium-mcp) provides a comprehensive set of tools for AI assistants to interact with VSCode and coordinate taskspace orchestration.
Tool Categories
- IDE Integration Tools - Get selections and navigate code structure
- Code Walkthrough Tools - Create interactive code tours and explanations
- Synthetic Pull Request Tools - Generate and manage code reviews
- Taskspace Orchestration Tools - Create and coordinate collaborative workspaces
- Reference System Tools - Manage compact reference storage and retrieval
- Rust Development Tools -
Explore Rust crate sources and examples
Agent Initialization System
The MCP server provides the foundation for dynamic agent initialization through the yiasou prompt system and embedded guidance resources. For complete details, see Guidance and Initialization.
Key capabilities:
@yiasoustored prompt with taskspace context- Embedded guidance resources like
main.mdandwalkthrough-format.md.- These can fetched using the
expand_referencetool from the embedded reference system.
- These can fetched using the
Architecture
The MCP server operates as a bridge between AI assistants and the VSCode extension:
- Process Discovery: Automatically discovers the parent VSCode process
- IPC Communication: Connects to the daemon message bus via Unix socket
- Tool Execution: Processes MCP tool calls and routes them appropriately
- Resource Serving: Provides embedded guidance files as MCP resources
- Dynamic Prompts: Assembles context-aware initialization prompts
- Response Handling: Returns structured results to the AI assistant
Configuration
The server is configured through your AI assistant's MCP settings:
{
"mcpServers": {
"symposium": {
"command": "/path/to/symposium-mcp",
"args": ["server"]
}
}
}
Error Handling
All tools include comprehensive error handling:
- IPC Failures: Graceful degradation when VSCode connection is lost
- Invalid Parameters: Clear error messages for malformed requests
- Process Discovery: Fallback mechanisms for PID detection
- Resource Loading: Fallback to basic prompts when guidance unavailable
- Context Fetching: Yiasou prompt works even without taskspace context
- Test Mode: Mock responses when
DIALECTIC_TEST_MODE=1is set
IDE Integration Tools
get_selection
#![allow(unused)] fn main() { // --- Tool definition ------------------ #[tool( description = "\ Get the currently selected text from any active editor in VSCode.\n\ Works with source files, review panels, and any other text editor.\n\ Returns null if no text is selected or no active editor is found.\ " )] async fn get_selection(&self) -> Result<CallToolResult, McpError> { }
Returns: { selectedText: string | null }
Use case: Retrieve user-selected code for analysis or modification
ide_operation
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Deserialize, Serialize, schemars::JsonSchema)] struct IdeOperationParams { /// Dialect program to execute program: String, } // --- Tool definition ------------------ #[tool( description = "\ Execute IDE operations using a structured JSON mini-language.\n\ This tool provides access to VSCode's Language Server Protocol (LSP) capabilities\n\ through a composable function system.\n\ \n\ Common operations:\n\ - findDefinitions(\"MyFunction\") or findDefinition(\"MyFunction\") - list of locations where a symbol named `MyFunction` is defined\n\ - findReferences(\"MyFunction\") - list of locations where a symbol named `MyFunction` is referenced\n\ \n\ To find full guidelines for usage, use the `expand_reference` with `walkthrough-format.md`.\n\ " )] async fn ide_operation( &self, Parameters(params): Parameters<IdeOperationParams>, ) -> Result<CallToolResult, McpError> { }
Common Dialect functions:
findDefinitions("symbol")- Find where a symbol is definedfindReferences("symbol")- Find all uses of a symbolsearch("file.rs", "pattern")- Search file for regex patternsearch("dir", "pattern", ".rs")- Search directory for pattern in specific file types
Use case: Navigate code structure, find definitions, search for patterns
Code Walkthrough Tools
present_walkthrough
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Clone, Deserialize, Serialize, JsonSchema)] pub struct PresentWalkthroughParams { /// Markdown content with embedded XML elements (comment, gitdiff, action, mermaid) /// See dialectic guidance for XML element syntax and usage pub content: String, /// Base directory path for resolving relative file references #[serde(rename = "baseUri")] pub base_uri: String, } // --- Tool definition ------------------ #[tool( description = "\ Display a code walkthrough in the user's IDE.\n\ Use this when the user\n\ (1) requests a walkthrough or that you walk through code or\n\ (2) asks that you explain how code works.\n\ \n\ Accepts markdown content with special code blocks.\n\ \n\ To find full guidelines for usage, use the `expand_reference` with `walkthrough-format.md`.\n\ \n\ Quick tips:\n\ \n\ Display a mermaid graph:\n\ ```mermaid\n\ (Mermaid content goes here)\n\ ```\n\ \n\ Add a comment to a particular line of code:\n\ ```comment\n\ location: findDefinition(`symbol_name`)\n\ \n\ (Explanatory text goes here)\n\ ```\n\ \n\ Add buttons that will let the user send you a message:\n\ ```action\n\ button: (what the user sees)\n\ \n\ (what message you will get)\n\ ```\n\ " )] async fn present_walkthrough( &self, Parameters(params): Parameters<PresentWalkthroughParams>, ) -> Result<CallToolResult, McpError> { }
Supported XML elements:
<comment location="EXPR" icon="ICON">content</comment>- Code comments at specific locations<action button="TEXT">message</action>- Interactive buttons<mermaid>diagram</mermaid>- Architecture diagrams
Use case: Create interactive code tours and explanations
Synthetic Pull Request Tools 
request_review
Implementation pending - will generate structured code reviews from commits.
Use case: Generate structured code reviews from commits
update_review
Implementation pending - will update existing code reviews.
// --- Tool definition ------------------
**Use case**: Manage review workflows and collect user feedback
## `get_review_status`
```rust
// --- Tool definition ------------------
Use case: Check review state and progress
Taskspace Orchestration Tools
spawn_taskspace
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Deserialize, Serialize, schemars::JsonSchema)] struct SpawnTaskspaceParams { /// Name for the new taskspace name: String, /// Description of the task to be performed task_description: String, /// Initial prompt to provide to the agent when it starts initial_prompt: String, /// Collaborator for the new taskspace (optional, defaults to current taskspace's collaborator) collaborator: Option<String>, } // --- Tool definition ------------------ #[tool( description = "Create a new taskspace with name, description, and initial prompt. \ The new taskspace will be launched with VSCode and the configured agent tool." )] async fn spawn_taskspace( &self, Parameters(params): Parameters<SpawnTaskspaceParams>, ) -> Result<CallToolResult, McpError> { }
Use case: Create new collaborative workspaces for specific tasks
update_taskspace
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Deserialize, Serialize, schemars::JsonSchema)] struct UpdateTaskspaceParams { /// New name for the taskspace name: String, /// New description for the taskspace description: String, /// Collaborator for the taskspace (optional) collaborator: Option<String>, } // --- Tool definition ------------------ #[tool( description = "Update the name and description of the current taskspace. \ Use this to set meaningful names and descriptions based on user interaction." )] async fn update_taskspace( &self, Parameters(params): Parameters<UpdateTaskspaceParams>, ) -> Result<CallToolResult, McpError> { }
Use case: Update taskspace name and description based on user interaction
delete_taskspace
Use case: Delete the current taskspace, removing filesystem directories, closing VSCode windows, and cleaning up git worktrees
log_progress
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Deserialize, Serialize, schemars::JsonSchema)] struct LogProgressParams { /// Progress message to display message: String, /// Category for visual indicator (info, warn, error, milestone, question) category: String, } // --- Tool definition ------------------ #[tool(description = "Report progress with visual indicators. \ Categories: 'info' or ℹ️, 'warn' or ⚠️, 'error' or ❌, 'milestone' or ✅, 'question' or ❓")] async fn log_progress( &self, Parameters(params): Parameters<LogProgressParams>, ) -> Result<CallToolResult, McpError> { }
Progress categories:
#![allow(unused)] fn main() { #[derive(Debug, Clone, Deserialize, Serialize)] #[serde(rename_all = "lowercase")] pub enum ProgressCategory { Info, Warn, Error, Milestone, Question, } }
Use case: Keep users informed of agent progress and status
signal_user
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Deserialize, Serialize, schemars::JsonSchema)] struct SignalUserParams { /// Message describing why user attention is needed message: String, } // --- Tool definition ------------------ #[tool(description = "Request user attention for assistance. \ The taskspace will be highlighted and moved toward the front of the panel.")] async fn signal_user( &self, Parameters(params): Parameters<SignalUserParams>, ) -> Result<CallToolResult, McpError> { }
Use case: Alert users when agents need help or input
Reference System Tools
expand_reference
#![allow(unused)] fn main() { // --- Parameters ----------------------- #[derive(Debug, Serialize, Deserialize, schemars::JsonSchema)] pub struct ExpandReferenceParams { /// The reference ID to expand pub id: String, } // --- Tool definition ------------------ #[tool(description = " Expand a compact reference (denoted as `<symposium-ref id='..'/>`) to get full context. \ Invoke with the contents of `id` attribute. Returns structured JSON with all available context data. \ ")] async fn expand_reference( &self, Parameters(params): Parameters<ExpandReferenceParams>, ) -> Result<CallToolResult, McpError> { }
Use case: Retrieve stored context for compact references. Also retrieves the bootup prompt ("yiasou") and the various guidance files that are embedded (e.g., "main.md").
Rust Development Tools
The Rust development tools help agents work with Rust crates by providing access to source code, examples, and documentation.
get_rust_crate_source
Purpose: Extract and optionally search Rust crate source code from crates.io
Parameters:
crate_name(required): Name of the crate (e.g., "tokio")version(optional): Semver range (e.g., "1.0", "^1.2", "~1.2.3")pattern(optional): Regex pattern for searching within sources
Behavior:
- Without pattern: Extracts crate source and returns path information
- With pattern: Extracts crate source AND performs pattern search, returning matches
Version Resolution:
- If
versionspecified: Uses semver range to find latest matching version - If no
version: Checks current project's lockfile for the crate version - If not in project: Uses latest version from crates.io
Response Format:
Without pattern (extraction only):
{
"crate_name": "tokio",
"version": "1.35.0",
"checkout_path": "/path/to/extracted/crate",
"message": "Crate tokio v1.35.0 extracted to /path/to/extracted/crate"
}
With pattern (extraction + search):
{
"crate_name": "tokio",
"version": "1.35.0",
"checkout_path": "/path/to/extracted/crate",
"example_matches": [
{
"file_path": "examples/hello_world.rs",
"line_number": 8,
"context_start_line": 6,
"context_end_line": 10,
"context": "#[tokio::main]\nasync fn main() {\n tokio::spawn(async {\n println!(\"Hello from spawn!\");\n });"
}
],
"other_matches": [
{
"file_path": "src/task/spawn.rs",
"line_number": 156,
"context_start_line": 154,
"context_end_line": 158,
"context": "/// Spawns a new asynchronous task\n///\npub fn spawn<T>(future: T) -> JoinHandle<T::Output>\nwhere\n T: Future + Send + 'static,"
}
],
"message": "Crate tokio v1.35.0 extracted to /path/to/extracted/crate"
}
Key Features:
- Caching: Extracted crates are cached to avoid redundant downloads
- Project Integration: Automatically detects versions from current Rust project
- Example Priority: Search results separate examples from other source files
- Context Preservation: Includes surrounding code lines for better understanding
Common Usage Patterns:
- Explore API:
get_rust_crate_source(crate_name: "serde")- Get crate structure - Find Examples:
get_rust_crate_source(crate_name: "tokio", pattern: "spawn")- Search for usage patterns - Version-Specific:
get_rust_crate_source(crate_name: "clap", version: "^4.0", pattern: "derive")- Target specific versions
This tool enables agents to provide accurate, example-driven assistance for Rust development by accessing real crate source code rather than relying on potentially outdated training data.
The Symposium Reference System
The symposium reference system is a generic key-value store that allows VSCode extensions to share arbitrary context data with AI assistants.
Core Concept
Extensions create compact references like <symposium-ref id="uuid"/> and store arbitrary JSON context. AI agents expand these references to get the JSON and interpret it contextually based on its self-documenting structure.
Key insight: There is no fixed schema. The system stores (uuid, arbitrary_json_value) pairs where the JSON structure is determined by the extension and interpreted by the receiving agent.
Message Format
The payload structure for store_reference messages:
TypeScript (Extension):
interface StoreReferencePayload {
/** UUID key for the reference */
key: string;
/** Arbitrary JSON value - self-documenting structure determined by extension */
value: any;
}
Rust (MCP Server):
#![allow(unused)] fn main() { /// Payload for store_reference messages - generic key-value storage #[derive(Debug, Clone, Deserialize, Serialize)] pub struct StoreReferencePayload { /// UUID key for the reference pub key: String, /// Arbitrary JSON value - self-documenting structure determined by extension pub value: serde_json::Value, } }
Usage Examples
// Code selection context:
store_reference("uuid-1", {
relativePath: "src/auth.ts",
selectionRange: { start: {line: 10, column: 5}, end: {line: 15, column: 2} },
selectedText: "function validateToken() { ... }"
});
// File reference context:
store_reference("uuid-2", {
filePath: "README.md",
type: "documentation"
});
// Custom application context:
store_reference("uuid-3", {
queryType: "database_schema",
tableName: "users",
fields: ["id", "email", "created_at"]
});
Implementation
Storage: The MCP server stores references as HashMap<String, serde_json::Value> where the key is the UUID and the value is arbitrary JSON.
Retrieval: The expand_reference MCP tool returns the stored JSON value for AI agents to interpret contextually.
Current Issue
The Rust code tries to deserialize arbitrary JSON into a rigid ReferenceContext struct instead of storing it as generic serde_json::Value. This breaks the intended generic architecture.
Solution: Use serde_json::Value throughout the storage and retrieval pipeline.
Discuss in Symposium
How users can quickly share code context with AI assistants running in terminals by selecting code and clicking the chat icon.
User Experience
Goal: Make it effortless to give an AI assistant context about specific code without manual copying/pasting or complex explanations.
Workflow:
- User selects relevant code in VSCode editor
- Clicks the chat icon in the status bar or editor
- A compact reference appears in their active AI terminal(s)
- User can immediately ask questions about that code
User Flow
- Select Code: User highlights code they want to discuss
- Click Chat Icon: Triggers reference creation and distribution
- Reference Created: System generates
<symposium-ref id="..."/>and stores context - Auto-Route to Terminal: Reference sent to active AI-enabled terminals
- Immediate Use: User can ask AI about the code using the reference
Terminal Selection Logic
The extension automatically determines where to send the reference:
Single AI Terminal: Sends reference directly, no user interaction needed Multiple AI Terminals: Sends to all terminals (user sees reference in each) No AI Terminals: Shows warning to start an MCP-enabled terminal
Terminal Discovery: Extension tracks active terminals through:
- Marco/Polo discovery protocol with MCP servers
- Shell PID matching between VSCode terminals and MCP processes
- Real-time registry updates as terminals start/stop
Implementation Details
Reference Distribution:
The extension sends the compact reference (<symposium-ref id="..."/>) directly to terminal stdin, making it appear as if the user typed it. This provides immediate visual feedback and allows the user to see exactly what will be sent to the AI.
Multi-Window Support:
Each VSCode window maintains its own terminal registry through the global daemon, ensuring references are routed correctly even with multiple VSCode instances.
Error Handling:
- No AI Terminals: User gets clear warning message
- Terminal Discovery Failure: Graceful degradation with manual terminal selection
- Reference Storage Failure: User sees error but can retry
Message Flow
sequenceDiagram
participant User as User
participant Ext as VSCode Extension
participant Daemon as Message Bus Daemon
participant Term as Terminal
participant AI as AI Assistant
User->>Ext: Select code + click chat icon
Ext->>Daemon: store_reference(uuid, context)
Daemon->>Daemon: Store in reference system
Daemon->>Ext: Response (success confirmation)
Ext->>Term: Type <symposium-ref id="uuid"/> in terminal
User->>AI: Ask question about the code
AI->>Daemon: expand_reference(uuid)
Daemon->>AI: Return full context
AI->>User: Response with code understanding
Related Systems
This feature builds on the Symposium Reference System for context storage and retrieval.
Key Files
symposium/vscode-extension/src/extension.ts- Chat icon handling, terminal selection, reference distribution
Code Walkthroughs
Walkthroughs are interactive markdown documents that help explain code changes, architectural decisions, and system behavior. They combine standard markdown with specialized XML elements that can reference code locations, embed git diffs, and provide interactive elements.
Overview
The walkthrough system consists of three main components:
- Markdown + XML Format: Authors write walkthroughs using markdown with embedded XML elements (
<comment>,<action>,<mermaid>) - Server-side Parser: The MCP server's
walkthrough_parsermodule converts the markdown to HTML, resolving code locations and generating interactive elements - VSCode Integration: The VSCode extension renders the processed HTML in a webview with click handlers and interactive features
System Architecture
flowchart TD
A["Markdown + XML Elements"] -->|"Raw markdown<br/>with XML tags"| B["Walkthrough Parser<br/>(MCP Server)"]
B -->|"Processed HTML<br/>with data attributes"| C["VSCode Webview<br/>Extension"]
B -->|"Dialect expressions<br/>(location attributes)"| D["Dialect Interpreter<br/>(Code Queries)"]
D -->|"Resolved locations<br/>(file paths & line numbers)"| B
C -->|"User interactions<br/>(clicks, navigation)"| E["Click Handlers &<br/>Interactive Features<br/>(Comments, Actions, etc.)"]
Processing Pipeline
When a walkthrough is presented:
- Parsing: The
WalkthroughParserusespulldown_cmarkto parse markdown while identifying XML elements - Resolution: Dialect expressions in
locationattributes are evaluated to find code locations - HTML Generation: XML elements are converted to styled HTML with embedded data for interactivity
- VSCode Rendering: The extension displays the HTML in a webview and attaches click handlers
Walkthrough Format Overview
Walkthroughs are authored as standard markdown documents with embedded XML elements for interactive features:
<comment location="...">- Contextual comments at specific code locations<action button="...">- Interactive buttons for follow-up tasks<mermaid>- Architecture diagrams and flowcharts
The location attributes use Dialect expressions to target code locations (e.g., findDefinition("MyClass"), search("src/auth.rs", "async fn")).
For complete format specification and usage guidelines, see the AI guidance documentation.
Technical Implementation
Parsing Process
The WalkthroughParser in symposium/mcp-server/src/walkthrough_parser.rs handles the conversion from markdown+XML to interactive HTML:
- Markdown Parsing: Uses
pulldown_cmarkto parse markdown into a stream of events - XML Detection: Identifies inline and block-level XML elements (
<comment>,<action>,<mermaid>) - Sequential Processing: Processes events one by one, collecting content between opening and closing tags
- Element Resolution: For each XML element:
- Parses attributes using
quick_xml - Evaluates Dialect expressions in
locationattributes viaDialectInterpreter - Resolves code locations to file paths and line numbers
- Generates structured data for client-side interaction
- Parses attributes using
- HTML Generation: Converts resolved elements to styled HTML with embedded JSON data
Element Resolution Examples
Comment Element Processing
Input:
<comment location="findDefinition(`validateToken`)" icon="lightbulb">
This function validates authentication tokens
</comment>
Internal processing:
- Parse XML attributes:
location="findDefinition(validateToken)",icon="lightbulb" - Evaluate Dialect expression:
findDefinition(validateToken)→[{definedAt: {path: "src/auth.rs", start: {line: 42, column: 0}, ...}, ...}] - Generate comment data with unique ID and normalized locations
- Create HTML with click handlers
Output HTML:
<div class="comment-item" data-comment='{"id":"comment-uuid","locations":[{"path":"src/auth.rs","line":42,"column":0,...}],"comment":["This function validates authentication tokens"]}' style="cursor: pointer; border: 1px solid var(--vscode-panel-border); ...">
<div style="display: flex; align-items: flex-start;">
<div class="comment-icon" style="margin-right: 8px;">💡</div>
<div class="comment-content" style="flex: 1;">
<div class="comment-locations" style="font-weight: 500; ...">src/auth.rs:42</div>
<div class="comment-text">This function validates authentication tokens</div>
</div>
</div>
</div>
HTML Generation Strategy
The parser generates VSCode-compatible HTML with:
- CSS Variables: Uses VSCode theme colors (
var(--vscode-panel-border),var(--vscode-foreground), etc.) - Embedded Data: Stores structured data in
data-*attributes for click handlers - Icon Mapping: Converts icon names to emoji representations
- Location Display: Shows file paths and line numbers for easy navigation
VSCode Integration
Message Flow
- MCP Tool Call: AI agent calls
present_walkthroughwith markdown content - Server Processing: MCP server parses and resolves the walkthrough to HTML
- Extension Delivery: VSCode extension receives processed HTML via IPC message
- Webview Rendering: Extension injects HTML into webview and attaches handlers
Extension Implementation
In symposium/vscode-extension/src/extension.ts:
if (message.type === 'present_walkthrough') {
const walkthroughPayload = message.payload as PresentWalkthroughPayload;
// Set base URI for file resolution
this.walkthroughProvider.setBaseUri(walkthroughPayload.base_uri);
// Show walkthrough HTML content in webview
this.walkthroughProvider.showWalkthroughHtml(walkthroughPayload.content);
}
Webview Rendering
In symposium/vscode-extension/src/walkthroughWebview.ts:
// Inject server-rendered HTML directly
contentElement.innerHTML = message.content;
// Add placement icons to all dialectic links
addPlacementIcons();
// Process mermaid diagrams in the HTML content
processMermaidDiagrams();
// Restore user interaction state
restoreOffscreenState();
Click Handler Registration
The extension automatically attaches click handlers to:
- Comment elements: Navigate to code locations or show disambiguation dialog
- Action buttons: Send messages back to the AI agent
- Mermaid diagrams: Process and render using mermaid.js
Data Flow Example
For a complete walkthrough processing flow:
sequenceDiagram
participant AI as AI Agent
participant MCP as MCP Server
participant VS as VSCode Extension
participant User as User
AI->>MCP: present_walkthrough({<br/>content: "# Changes<br/><comment location='findDefinition(`User`)'>..."<br/>})
Note over MCP: Processing Pipeline
MCP->>MCP: 1. Parse markdown with pulldown_cmark
MCP->>MCP: 2. Identify XML: <comment location=...>
MCP->>MCP: 3. Evaluate: findDefinition(`User`)<br/>→ [{path:"src/user.rs", line:10}]
MCP->>MCP: 4. Generate HTML with data attributes
MCP->>VS: Send processed HTML via IPC
Note over VS: Webview Rendering
VS->>VS: 1. Inject into webview: innerHTML = ...
VS->>VS: 2. Attach click handlers to comments
VS->>VS: 3. Process mermaid diagrams
User->>VS: Click on comment
VS->>VS: Navigate to src/user.rs:10
Walkthrough Format
Note: Walkthrough format documentation is implemented in the MCP server but not currently extracted with anchors.
For complete format specification and usage guidelines, see the walkthrough parser implementation in the MCP server.
Walkthrough Comment Interactions
This document describes the design for interactive comment features in code walkthroughs, allowing users to reply to walkthrough comments and have those replies forwarded to the AI agent.
When a walkthrough is presented
- Unambiguous comments (exactly one location) are added into the VSCode comment system immediately.
- Ambiguous comments: when the user clicks, they are presented with a dialogue to select how to resolve.
- Once they select an option, the comment is rewritten to render as
file.rs:25and the comment is placed. - A magnifying glass icon remains that, if clicked, will allow the user to reselect the comment placement.
- When comment placement changes, the comment is moved to the new location in VSCode.
- Once they select an option, the comment is rewritten to render as
Comment display
Comments display as if they were authored by "AI Agent" -- we should let AI agents customize their names later.
Comments have a "reply" button. When clicked, it inserts a <symposium-ref> that maps to a JSON blob like:
{
"in-reply-to-comment-at": {
"file": "path/to/file.js",
"start": {
"line": 22,
},
"end": {
"line": 44,
},
"comment": "... the text that the AI placed at this location ..."
}
}
This is inserted into the AI chat and the user can type more.
User-added comments
VSCode includes a CommentProvider that is meant to permit users to add comments on specific lines. Symposium registers as a comment provider but comments added by the user are written into the AI Agent chat instead.
Dialect Language
The Dialect language is a superset of JSON with function call syntax for expressing and composing IDE operations. Any valid JSON is also valid Dialect.
Design Goals
Dialect is designed to be LLM-friendly - the syntax should feel natural and familiar to language models, matching the kind of pseudo-code they would generate intuitively:
- Function call syntax:
findDefinitions("MyClass")reads like natural pseudo-code - JSON superset: We accept JSON augmented with function calls but we are also tolerant of trailing commas, unquoted field names
The goal is to minimize the gap between "what an LLM wants to express" and "valid Dialect syntax", making code generation more reliable and the language more intuitive.
Quick Start
Find where a symbol is defined:
findDefinitions("MyFunction")
Find all references to a symbol:
findReferences("MyClass")
Get information about a symbol:
getSymbolInfo("methodName")
Composition - find references to all definitions:
findReferences(findDefinitions("MyFunction"))
Grammar
Program = Expr
Expr = FunctionCall
| JsonObject
| JsonArray
| JsonAtomic
FunctionCall = Identifier "(" ArgumentList? ")"
ArgumentList = Expr ("," Expr)* ","?
JsonObject = "{" (JsonProperty ("," JsonProperty)* ","?)? "}"
JsonProperty = (String | Identifier) ":" Expr
JsonArray = "[" (Expr ("," Expr)* ","?)? "]"
JsonAtomic = Number | String | Boolean | "null" | "undefined"
Identifier = [a-zA-Z_][a-zA-Z0-9_]*
String = "\"" ... "\"" // JSON string literal
Number = ... // JSON number literal
Boolean = "true" | "false"
Function Signatures
Functions are called with positional arguments in a defined order:
Core IDE Operations
findDefinitions(symbol: string)- Find where a symbol is definedfindReferences(symbol: string)- Find all references to a symbolgetSymbolInfo(symbol: string)- Get detailed symbol information
Search Operations
searchFiles(pattern: string, path?: string)- Search for text patternsfindFiles(namePattern: string, path?: string)- Find files by name
Dynamic Semantics
A Dialect expression E evaluates to a JSON value:
Function Calls
- If
E = Identifier(Expr...), then:- Evaluate each
Exprto valuesV... - Look up the function
Identifier - Call the function with positional arguments
V... - Return the function's result
- Evaluate each
JSON Values
- If
E = [ Expr... ], evaluate eachExprtoV...and return[ V... ] - If
E = { Property... }, evaluate each property value and return the object - If
E = number | string | boolean | null | undefined, evaluate to itself
Implementation
The parser is implemented in dialect/parser.rs. The interpreter in dialect.rs handles function dispatch.
Defining Functions
Functions implement the DialectFunction trait with parameter order specification:
#![allow(unused)] fn main() { pub trait DialectFunction<U: Send>: DeserializeOwned + Send { type Output: Serialize + Send; const PARAMETER_ORDER: &'static [&'static str]; async fn execute(self, interpreter: &mut DialectInterpreter<U>) -> anyhow::Result<Self::Output>; } }
Functions that represent values can implement DialectValue instead:
#![allow(unused)] fn main() { }
Error Handling
The parser provides detailed error messages with source location indicators:
error: Expected ')'
|
1 | findDefinitions("MyClass"
| ^
|
Symposium application specifics
Startup and Window Management 
Symposium maintains exactly one window open at any time, using three distinct window types for different application states.
Single Source of Truth Architecture
Critical Change: The application now uses AppDelegate as the single source of truth for ProjectManager instances.
Key Principles
- Single Owner: Only
AppDelegate.currentProjectManagerstores the ProjectManager - Observer Pattern: All views get ProjectManager via
@EnvironmentObject var appDelegate: AppDelegate - Graceful Degradation: Views handle
nilProjectManager by showing "No project selected" state - Clean Lifecycle: Setting
currentProjectManager = nilautomatically updates all views
Component Architecture
// ✅ CORRECT: Single source of truth
struct ProjectView: View {
@EnvironmentObject var appDelegate: AppDelegate
var body: some View {
if let projectManager = appDelegate.currentProjectManager {
// Use projectManager here
} else {
Text("No project selected")
}
}
}
// ❌ OLD: Direct references create cleanup issues
struct ProjectView: View {
let projectManager: ProjectManager // Creates duplicate reference
}
This architecture prevents reference leaks and ensures clean ProjectManager lifecycle management.
Three-Window Architecture
The application uses three distinct window types for different application states:
- Settings Window - for permissions and agent configuration
- Project Selection Window - for creating or opening projects
- Project Window - the main project workspace
Startup State Machine
The application follows a deterministic state machine on startup and window transitions:
stateDiagram-v2
[*] --> AppStart
AppStart --> Settings : Missing permissions
AppStart --> CheckProject : Has permissions
Settings --> AppStart : Window closed
CheckProject --> OpenProject : Valid current project
CheckProject --> ChooseProject : No current project
ChooseProject --> AppStart : Window closed (no selection)
ChooseProject --> CheckProject : Project path set
CheckProject --> OpenProject : Valid project path
OpenProject --> AppStart : Window closed (clears current project)
State Descriptions
AppStart: Entry point that validates permissions and current project state
- If the correct window for the current state is already open, takes no action
- Checks accessibility and screen recording permissions
- If missing permissions → Settings Window
- If has permissions → CheckProject
Settings: Regular window for permission management and agent configuration
- User grants required permissions
- User configures available agents
- When closed → AppStart (re-validates permissions)
ChooseProject: Project selection and creation interface
- Lists available agents with refresh capability
- Provides new project creation form
- Provides "Open existing project" file picker
- When project created or selected → sets
activeProjectPathand dismisses - Main app flow detects path change → CheckProject
- When closed without selection → AppStart
CheckProject: Validates the persisted current project
- Checks if current project path exists and is valid
- If valid project → OpenProject
- If no/invalid project → ChooseProject
OpenProject: Main project workspace window
- Displays project taskspaces and management interface
- When closed → clears current project and goes to AppStart
Window Management Implementation
Single Window Principle
The application typically maintains one window at a time, with the exception that Settings can be opened from any state:
func openWindow(id: String) {
if id != "settings" {
closeAllWindows()
}
// Open the requested window
}
func appStart() {
// If the project window is open and we have a valid current project, do nothing
if isProjectWindowOpen() && hasValidCurrentProject() {
return
}
// If settings window is open, do nothing (user is configuring)
if isSettingsWindowOpen() {
return
}
// Normal startup logic...
if !hasRequiredPermissions {
openWindow(id: "settings")
} else if let validCurrentProject = validateCurrentProject() {
openWindow(id: "open-project")
} else {
openWindow(id: "choose-project")
}
}
Window Close Handling
Window close handling requires careful distinction between "user clicked close button" and "window disappeared due to app shutdown":
.onReceive(NotificationCenter.default.publisher(for: NSWindow.willCloseNotification)) { notification in
// Only clear project when user explicitly closes the window
if let window = notification.object as? NSWindow,
window.identifier?.rawValue == "open-project" {
// Clear project and return to startup flow
appDelegate.currentProjectManager = nil
settingsManager.activeProjectPath = ""
appStart()
}
}
.onDisappear {
// NOTE: We don't handle project cleanup here because onDisappear
// fires both when user closes window AND when app quits.
// We only want to clear the project on explicit user close.
}
This ensures the project path persists between app launches when the user quits the app, but gets cleared when they explicitly close the project window.
Project Persistence
Current Project Storage
The current project is persisted in UserDefaults:
@AppStorage("activeProjectPath") var activeProjectPath: String = ""
Project Metadata
Each project stores metadata in project.json:
{
"version": 1,
"id": "uuid-string",
"name": "Project Name",
"gitURL": "https://github.com/user/repo.git",
"directoryPath": "/path/to/Project.symposium",
"agent": "claude-code",
"defaultBranch": null,
"createdAt": "2025-01-01T00:00:00Z",
"taskspaces": []
}
Default Branch Handling
The defaultBranch field controls which branch new taskspaces start from:
- If
defaultBranchis specified: Use that remote/branch (e.g.,main,origin/foo, etc.) - If
defaultBranchis null/empty: Auto-detect the default branch from origin remote (e.g.,origin/main) - Auto-detection uses
git symbolic-ref refs/remotes/origin/HEADor falls back toorigin/main - New taskspace worktrees are created from the specified or detected remote branch
Validation Logic
On startup, the application validates the current project:
- Check if
activeProjectPathexists as directory - Check if
project.jsonexists and is valid JSON - Check if version number is supported
- If any validation fails → clear current project, go to ChooseProject
Project Creation and Opening Flow
Project Creation
The ChooseProject window includes a comprehensive project creation form that:
- Collects project metadata (name, git URL, directory, agent, etc.)
- Creates the project directory structure and
project.json - Sets
activeProjectPathto the new project directory - Dismisses the dialog
- Main app flow detects the path change and validates/opens the project
Project Opening
The project opening flow:
- User selects existing project directory via file picker
- Sets
activeProjectPathto the selected directory - Dismisses the dialog
- Main app flow detects the path change and validates/opens the project
Single ProjectManager Creation Point
This architecture ensures that ProjectManager instances are only created in one place - the main app flow when validating and opening projects. The dialogs are purely UI for collecting user input and setting the project path.
New Project Form
The ChooseProject window includes a comprehensive project creation form:
- Project Name: Used for directory name (
Name.symposium) - SSH Host: Currently localhost only (placeholder for future remote projects)
- Directory Location: Parent directory with browse button
- Origin Git Repository: Initial repository to clone
- Additional Remotes: Extra git remotes with custom names
- Editor: VSCode only (placeholder for future editor support)
- AI Agent: Selection from available agents, including "None" option
Advanced Settings (collapsible section):
- Default Branch for New Taskspaces: Branch name to use when creating new taskspaces (defaults to origin's default branch if empty)
Agent Selection
The agent selection uses the same widget as Settings but in selectable mode:
- Lists all available agents from
AgentManager.availableAgents - Includes "Refresh" button to rescan for agents
- Includes "None" option for projects without AI assistance
- Selected agent is stored in project metadata
Project Directory Structure
New projects create this structure:
ProjectName.symposium/
├── project.json # Project metadata
├── .git/ # Bare git repository
└── taskspaces/ # Individual taskspace directories
Error Handling
Validation Failures
When validation fails during CheckProject:
- Log the specific failure reason
- Show user notification explaining what happened
- Clear
activeProjectPath - Proceed to ChooseProject
Missing Agents
If a project's selected agent is no longer available:
- Allow the project to open (don't block on missing agents)
- Show warning in project window about missing agent
- User will discover the issue when attempting to use agent features
Corrupted Project Files
If project.json is corrupted or unreadable:
- Show user notification: "Project file corrupted, please select a different project"
- Treat as validation failure
- Clear current project and go to ChooseProject
- User can attempt to recover or create new project
Implementation Notes
Window IDs
The application uses four SwiftUI WindowGroup IDs:
"splash"- Startup coordinator window (auto-opened by SwiftUI, immediately closes itself)"settings"- Settings window"choose-project"- Project selection window"open-project"- Main project window
Startup Window Handling
Since SwiftUI automatically opens the first WindowGroup, the splash window serves as a startup coordinator:
WindowGroup(id: "splash") {
SplashCoordinatorView()
.onAppear {
// Brief delay to show the amusing message
DispatchQueue.main.asyncAfter(deadline: .now() + 0.8) {
appStart()
closeWindow(id: "splash")
}
}
}
The splash window:
- Opens automatically when the app launches
- Shows a brief Socratic-themed message (e.g., "Preparing the symposium...", "Gathering the philosophers...", "Arranging the dialogue...", "Calling the assembly to order...")
- Triggers the
appStart()logic after a short delay - Closes itself once startup is complete
- Never reopens during the app session
Race Condition Resolution
A critical implementation challenge was a race condition where project restoration happened before agent scanning completed, causing "waiting for daemon" issues. The solution was to wait for agentManager.scanningCompleted before attempting project restoration:
private func runStartupLogic() {
// Check if agents are ready (needed for project restoration)
if !agentManager.scanningCompleted {
Logger.shared.log("App: Agent scan not complete, waiting...")
DispatchQueue.main.asyncAfter(deadline: .now() + 0.5) {
self.runStartupLogic()
}
return
}
// ... rest of startup logic
}
Automatic Window Refresh
To improve user experience, the system automatically calls reregisterWindows() after project restoration to re-establish VSCode window connections without requiring manual refresh button clicks:
// Automatically refresh window connections on startup
DispatchQueue.main.asyncAfter(deadline: .now() + 1.0) {
self.reregisterWindows(for: projectManager)
}
State Coordination
The main App struct acts as the coordinator:
- No separate AppCoordinator class needed
appStart()function handles all state logic- State is implicit in the currently executing code path
Permission Checking
Reuses existing permission management:
permissionManager.hasAccessibilityPermissionpermissionManager.hasScreenRecordingPermissionpermissionManager.checkAllPermissions()
This architecture provides a clean, predictable user experience while maintaining the flexibility to extend functionality in the future.
Agent Initialization Integration
The startup and window management system integrates with the MCP-based agent initialization system documented in @guidance-and-initialization.md.
Agent Startup Flow
When a taskspace is opened in VSCode:
- VSCode Extension detects taskspace directory and loads MCP server
- MCP Server connects to Symposium daemon via IPC
- Agent requests initialization via
expand_reference("yiasou") - MCP Server fetches taskspace state using unified TaskspaceState protocol
- Dynamic prompt assembly includes real taskspace context (name, description, initial_prompt)
- Agent receives comprehensive initialization with embedded guidance and project context
TaskspaceState Protocol Integration
The window management system works with the TaskspaceState protocol:
- Read operations: Agent initialization fetches current taskspace state
- Write operations:
update_taskspacetool modifies taskspace properties and clears initial_prompt - State transitions: Taskspace automatically transitions from
hatchling→resumeafter first agent interaction - UI updates: Changes are persisted to disk and reflected in the Symposium GUI
Coordination with Project Manager
The ProjectManager handles TaskspaceState IPC messages:
func handleTaskspaceState(_ payload: TaskspaceStateRequest, messageId: String) async
-> MessageHandlingResult<TaskspaceStateResponse>
{
// Handle both read and write operations
// Update taskspace properties if provided
// Return current state with appropriate initial_prompt value
// Persist changes and update UI
}
This integration ensures seamless coordination between the GUI application's window management and the agent's dynamic initialization system.
Stacked Windows
Overview
Stacked windows is a per-project feature that creates a "deck of cards" effect where all taskspace windows occupy the same screen position. When enabled, clicking a taskspace brings its window to the front while positioning all other taskspace windows at the exact same location behind it. This creates a clean, organized workspace where users can quickly switch between taskspaces without window clutter.
User Experience
Basic Behavior
- Per-project setting: Each project can independently enable/disable stacked windows via a checkbox in the project header
- Persistent storage: Setting is stored in
project.jsonand travels with the project - Normal mode: When disabled, clicking taskspaces focuses windows normally
- Stacked mode: When enabled, clicking a taskspace brings it to front and positions all other taskspace windows at the same location
Window Following
When stacked windows is enabled and the user interacts with any window in the stack:
- Drag following: All stacked windows move together as a cohesive unit during drag operations
- Resize following: All stacked windows resize to match when any window is resized
- Following happens during the operation at 20fps (50ms intervals)
- No manual repositioning needed - the illusion of a single window is maintained
Technical Architecture
Core Components
ProjectManager Integration
stackedWindowsEnabledproperty added to Project model (version 2)setStackedWindowsEnabled()method updates setting and saves to diskfocusWindowWithStacking()implements the core stacking logic
WindowStackTracker
- Handles drag and resize detection with window following
- Uses AeroSpace-inspired event-driven approach
- Manages peer window relationships (no leader/follower hierarchy)
Implementation Philosophy
The implementation follows research documented in:
- Window Stacking Design - Original design goals and approach
- AeroSpace Approach to Window Following - Reliable drag detection strategy
Why Not AXObserver?
Traditional macOS window management relies on AXObserver notifications for tracking window movement. However, this approach has significant reliability issues:
- Only ~30% application compatibility
- Frequent notification failures
- Complex state management
- Performance overhead from continuous monitoring
AeroSpace-Inspired Solution
Instead, we use an event-driven polling approach:
- CGEvent Tap: System-wide mouse event detection
- Interaction Detection: Identify when user starts dragging or resizing any tracked window
- Timer-Based Polling: Track active window position and size only during interactions (50ms intervals)
- Synchronous Following: Move and resize all other windows to match the active window
This provides:
- 90%+ application compatibility
- Reliable cross-application window management
- Minimal CPU overhead (polling only during interactions)
- Low latency response (20fps during operations)
Data Storage
Project Schema Evolution
Stacked windows required updating the project schema from version 1 to version 2:
struct Project: Codable {
let version: Int // Now 2
// ... existing fields ...
var stackedWindowsEnabled: Bool = false // New field
}
Migration Strategy
The implementation includes proper migration logic:
- Version 1 projects automatically upgrade to version 2
stackedWindowsEnableddefaults tofalsefor migrated projects- Version 0 (legacy) projects also supported through fallback migration
This establishes a clean precedent for future schema upgrades.
Implementation Details
Window Positioning and Synchronization
When a taskspace is activated in stacked mode:
- Focus Target: Bring target window to front using standard macOS APIs
- Get Bounds: Retrieve target window position and size
- Position Others: Move all other taskspace windows to exact same bounds
- Start Tracking: Initialize interaction detection for all windows in the stack
Interaction Following Process
// Simplified flow
func handleMouseEvent(type: CGEventType, event: CGEvent) {
switch type {
case .leftMouseDown:
if trackedWindowIDs.contains(clickedWindow) {
startTracking(activeWindow: clickedWindow) // Begin 50ms polling
}
case .leftMouseUp:
stopActiveTracking() // End polling
}
}
func updateOtherWindows() {
let positionDelta = currentPosition - lastPosition
let hasResize = currentSize != lastSize
for otherWindow in otherWindows {
if hasMovement && hasResize {
moveAndResizeWindow(otherWindow, positionDelta: positionDelta, newSize: currentSize)
} else if hasMovement {
moveWindow(otherWindow, by: positionDelta)
} else if hasResize {
resizeWindow(otherWindow, to: currentSize)
}
}
}
Resource Management
- Event Tap: Created once, reused across all tracking sessions
- Timer: Only active during interaction operations (typically 1-3 seconds)
- Cleanup: Automatic cleanup when disabling stacked mode or closing projects
- Memory: Minimal overhead - just window ID tracking and position/size deltas
Edge Cases and Limitations
Current Limitations
- IDE Windows Only: Currently applies only to VSCode windows (taskspace windows)
- Single Stack: All taskspace windows form one stack (no multiple stacks)
- Manual Recovery: If windows get out of sync, switching taskspaces re-aligns them
Handled Edge Cases
- Window Closure: Stale window references are automatically cleaned up
- Project Switching: Tracking stops when switching or closing projects
- Mode Toggling: Disabling stacked windows stops all tracking
- Application Crashes: Event tap and timers are properly cleaned up
Future Enhancements
Planned Improvements
- Multiple Window Types: Extend to terminal windows, browser windows, etc.
- Multiple Stacks: Support for organizing windows into different stacks
- Visual Indicators: Subtle visual cues showing stack membership
- Keyboard Shortcuts: Quick switching between stacked windows
Performance Optimizations
- Adaptive Polling: Slower polling for small movements, faster for large movements
- Movement Prediction: Anticipate window movement for smoother following
- Batch Updates: Group multiple window moves into single operations
Success Metrics
The stacked windows implementation is considered successful based on:
- Movement Coherence: Dragging any window moves all others seamlessly ✅
- Resize Coherence: Resizing any window resizes all others to match ✅
- Visual Isolation: Only the active window is visible during normal operation ✅
- Reliable Switching: Users can switch between windows without position drift ✅
- System Stability: No performance impact or conflicts with macOS window management ✅
- Persistent Settings: Per-project configuration survives app restarts ✅
Conclusion
Stacked windows provides a clean, efficient way to manage multiple taskspace windows by creating the illusion of a single window that can be quickly switched between different contexts. The AeroSpace-inspired interaction detection ensures reliable window following across diverse applications while maintaining excellent performance characteristics.
The peer-based architecture allows any window in the stack to be the one the user interacts with, providing a natural and intuitive experience. Both drag and resize operations are synchronized across all windows in the stack, maintaining the illusion of working with a single window.
The implementation establishes solid patterns for future window management features and demonstrates how to build reliable cross-application window coordination on macOS.
Window Stacking Design
Problem Statement
In Symposium we wish to create the illusion of there being only one taskspace visible at a time. We achieve this by creating a "stack" of windows where the leader taskspace is on-top and the others ("followers") are underneath, making them invisible. The problem is that when the leader is moved, we need to ensure that the followers move as well or the illustion will be ruined. This document explores our design for achieving this in a smooth fashion.
Design Goals
- Single visible window: Only the active ("leader") window should be visible at any time
- Cohesive movement: When the leader window is moved, all stacked windows move together
- Reliable tracking: Changes in window position should be detected promptly and accurately
- Smooth transitions: Switching between windows in a stack should be fluid
- Minimal performance impact: Window tracking should not significantly impact system resources
Technical Approach
Leader/Follower Architecture
Each window stack consists of:
- Leader window: The currently visible window that responds to user interaction
- Follower windows: Hidden windows that track the leader's position
Only one window per stack acts as the leader at any time. All follower windows are positioned slightly inside the leader window's bounds to ensure they remain hidden even during movement lag.
Inset Positioning Strategy
Follower windows are positioned with a configurable inset relative to the leader window:
Leader window: (x, y, width, height)
Follower window: (x + inset, y + inset, width - 2*inset, height - 2*inset)
Default inset: 10% of window dimensions
Example calculation:
- Leader at (100, 100) with size 1000×800
- 10% inset = 100px horizontal, 80px vertical
- Follower at (150, 140) with size 900×720
This inset serves multiple purposes:
- Lag compensation: Even with 50-100ms notification delays, followers won't peek out during movement
- Click protection: Prevents accidental interaction with hidden follower windows
- Visual clarity: Makes the leader window unambiguously the active one
Movement Tracking with Event-Driven Polling
Note: This approach replaces the original AXObserver notification system which proved unreliable across macOS applications.
Window position tracking uses an AeroSpace-inspired event-driven polling system:
- CGEvent tap detects mouse clicks on any window system-wide
- Identify leader window by comparing clicked window with current stack leader
- Start timer-based polling (20ms interval) during drag operations
- Position delta calculation tracks leader movement and applies to followers
- Stop polling when drag operation completes
This approach provides:
- 90%+ application compatibility (vs ~30% with AXObserver)
- Minimal CPU overhead (polling only during active drags)
- Low latency (20ms response time during movement)
- Reliable detection across diverse application architectures
Leader Election and Handoff
When switching the active window in a stack:
- Stop position tracking for current leader window
- Resize and reposition old leader to follower dimensions/position
- Resize and reposition new leader to leader dimensions/position
- Raise new leader to top in window depth ordering
- Update leader reference for drag detection system
This handoff pattern ensures:
- No conflicting position tracking during transitions
- Clean separation between user-initiated and system-initiated position changes
- Immediate activation of drag detection for new leader
Implementation Details
Configuration Options
| Parameter | Default | Range | Description |
|---|---|---|---|
| Inset percentage | 10% | 5-20% | Follower window inset as percentage of leader size |
| Minimum inset | 10px | 5-50px | Absolute minimum inset for very small windows |
| Maximum inset | 150px | 50-300px | Absolute maximum inset for very large windows |
| Notification timeout | 200ms | 100-500ms | Max wait time for position updates |
Edge Cases and Mitigations
Very Small Windows
- Apply minimum absolute inset (10px) regardless of percentage
- May result in minimal visual separation but preserves functionality
Very Large Windows
- Apply maximum absolute inset (150px) to avoid excessive unused space
- Maintains reasonable follower window usability
Manual Follower Movement
- Followers moved manually (via Mission Control, etc.) are ignored
- Position will be corrected on next leader switch
- Alternative: Periodic position verification (future enhancement)
System-Initiated Movement
- Display configuration changes may move all windows
- Leader movement notifications will trigger follower repositioning
- Natural recovery through normal tracking mechanism
Application Misbehavior
- Some applications may resist programmatic repositioning
- Error handling should gracefully exclude problematic windows from stacks
- Logging available for debugging positioning failures
User Interface Integration
Stack Management Window
A separate monitoring window provides:
- List of active stacks with window counts
- Visual indication of current leader in each stack
- Click-to-switch functionality
- Future: Periodic thumbnail snapshots of stack contents
Visual Indicators
Current approach: Separate monitoring window Future possibilities:
- Wider background window creating subtle drop shadow
- Menu bar indicator with stack picker
- Dock integration with notification badges
Performance Considerations
Event Detection Efficiency
- Single CGEvent tap monitors system-wide mouse events
- Event filtering occurs in kernel space for minimal overhead
- Timer-based polling activated only during drag operations (typically 1-3 seconds)
Movement Latency
- 20ms polling interval provides smooth 50fps tracking during drags
- Sub-frame response time for typical window movements
- Zero overhead when no drag operations are active
Memory Usage
- Minimal overhead: notification observers and window position tracking
- No additional window content rendering or capture required
- Scales linearly with number of active stacks
Future Enhancements
Animated Transitions
- Smooth resize/reposition animations during leader switches
- Configurable animation duration and easing
- May require Core Animation integration
Advanced Visual Indicators
- Semi-transparent follower window previews
- Stack depth indicators
- Drag handles or manipulation widgets
Multi-Stack Management
- Named stacks with persistence
- Drag-and-drop between stacks
- Keyboard shortcuts for stack navigation
Application Integration
- VS Code extension for automatic window stacking
- Terminal session integration
- WebSocket API for programmatic control
Implementation Phases
Phase 1: Core Functionality ✓
- Basic window stacking and switching
- Manual add/remove from stacks
- Simple position synchronization
Phase 2: Movement Tracking ✓
Implement kAXMovedNotification system(replaced with event-driven polling)- Implement AeroSpace-inspired drag detection with CGEvent taps
- Add timer-based position tracking during active drags
- Add inset positioning for followers
- Create leader election and handoff logic
Phase 3: Enhanced UX
- Stack monitoring window
- Configuration options
- Improved error handling and edge cases
Phase 4: Advanced Features
- Animation system
- Multiple stack support
- External API integration
Success Criteria
The window stacking implementation will be considered successful when:
- Movement coherence: Dragging the leader window moves all followers seamlessly
- Visual isolation: Only the leader window is visible during normal operation
- Reliable switching: Users can switch between windows in a stack without position drift
- System stability: No performance impact or conflicts with macOS window management
- Edge case handling: Graceful behavior during display changes, app crashes, and unusual scenarios
This design provides a solid foundation for implementing true window stacking behavior while maintaining system compatibility and user experience quality.
Window Stacking Scenario Walkthrough
This document traces through a typical window stacking scenario, detailing the expected behavior and state changes at each step.
Initial Setup
- Inset Percentage: 10% (0.10)
- Minimum Inset: 10px
- Maximum Inset: 150px
Scenario Steps
Step 1: Add Window 1 (Becomes Leader)
Action: User adds first Safari window to stack
Initial State:
Window 1 (Safari #115809):
- Original Position: (673, 190)
- Original Size: 574 × 614
- Role: Not in stack
Operations:
- Store original frame:
(673, 190, 574, 614) - Mark as leader:
isLeader = true - Set as current leader window
- Setup drag detection for this window
- Focus window (bring to front)
Final State:
Window 1 (Safari #115809):
- Position: (673, 190) [unchanged]
- Size: 574 × 614 [unchanged]
- Role: LEADER
- Stored Original Frame: (673, 190, 574, 614)
- Z-Order: Front
Stack: [Window 1 (LEADER)]
Step 2: Add Window 2 (Becomes Follower)
Action: User adds second Safari window to stack
Initial State:
Window 1 (Safari #115809):
- Position: (673, 190)
- Size: 574 × 614
- Role: LEADER
Window 2 (Safari #115807):
- Original Position: (729, 251)
- Original Size: 574 × 491
- Role: Not in stack
Calculations:
Leader Frame: (673, 190, 574, 614)
Horizontal Inset = max(10, min(150, 574 × 0.10)) = 57.4px
Vertical Inset = max(10, min(150, 614 × 0.10)) = 61.4px
Follower Frame:
- X: 673 + 57.4 = 730.4
- Y: 190 + 61.4 = 251.4
- Width: 574 - (2 × 57.4) = 459.2
- Height: 614 - (2 × 61.4) = 491.2
Operations:
- Store Window 2's original frame:
(729, 251, 574, 491) - Calculate follower frame based on current leader
- Move Window 2 to follower position:
(730.4, 251.4, 459.2, 491.2) - Mark as follower:
isLeader = false - Send Window 2 to back (behind leader)
- Do NOT switch leadership
- Do NOT focus Window 2
Final State:
Window 1 (Safari #115809):
- Position: (673, 190) [unchanged]
- Size: 574 × 614 [unchanged]
- Role: LEADER
- Z-Order: Front
Window 2 (Safari #115807):
- Position: (730.4, 251.4)
- Size: 459.2 × 491.2
- Role: FOLLOWER
- Stored Original Frame: (729, 251, 574, 491)
- Z-Order: Behind Window 1
Stack: [Window 1 (LEADER), Window 2 (FOLLOWER)]
Step 3: User Drags Window 1
Action: User clicks and drags Window 1 by 50px right, 30px down
Initial State:
Window 1: Position (673, 190), Size (574, 614), LEADER
Window 2: Position (730.4, 251.4), Size (459.2, 491.2), FOLLOWER
Drag Detection:
- CGEvent tap detects mouse down on Window 1
- Verify it's our leader window (ID matches)
- Start PositionTracker with 20ms polling
During Drag (each 20ms poll):
Poll 1: Window 1 at (673, 190) → no change
Poll 2: Window 1 at (680, 193) → delta (+7, +3)
- Move Window 2 to (737.4, 254.4)
Poll 3: Window 1 at (695, 201) → delta (+15, +8)
- Move Window 2 to (745.4, 259.4)
...
Final: Window 1 at (723, 220) → delta (+28, +19)
- Move Window 2 to (758.4, 270.4)
On Mouse Up:
- Stop PositionTracker
- Update stored positions
Final State:
Window 1 (Safari #115809):
- Position: (723, 220) [moved +50, +30]
- Size: 574 × 614 [unchanged]
- Role: LEADER
Window 2 (Safari #115807):
- Position: (780.4, 281.4) [moved +50, +30]
- Size: 459.2 × 491.2 [unchanged]
- Role: FOLLOWER
Step 4: User Clicks "Next" (Window 2 Becomes Leader)
Action: User clicks Next button to switch leadership
Initial State:
Window 1: Position (723, 220), Size (574, 614), LEADER
Window 2: Position (780.4, 281.4), Size (459.2, 491.2), FOLLOWER
Operations:
-
Update leader flags:
- Window 1:
isLeader = false - Window 2:
isLeader = true
- Window 1:
-
Resize Window 1 to follower size:
Current Leader Frame: (723, 220, 574, 614) Horizontal Inset = 57.4px Vertical Inset = 61.4px New Window 1 Frame: - X: 723 + 57.4 = 780.4 - Y: 220 + 61.4 = 281.4 - Width: 574 - 114.8 = 459.2 - Height: 614 - 122.8 = 491.2 -
Restore Window 2 to its original size:
Use stored original frame: (729, 251, 574, 491) But maintain current position relationship: - Window 2 was at (780.4, 281.4) as follower - Needs to expand back to original size (574 × 491) - New position: (723, 220) [same as old leader position] -
Apply changes:
- Move/resize Window 1 to
(780.4, 281.4, 459.2, 491.2) - Move/resize Window 2 to
(723, 220, 574, 491) - Focus Window 2 (brings to front)
- Send Window 1 to back
- Move/resize Window 1 to
-
Update drag detection:
- Stop tracking Window 1
- Start tracking Window 2
Final State:
Window 1 (Safari #115809):
- Position: (780.4, 281.4)
- Size: 459.2 × 491.2
- Role: FOLLOWER
- Z-Order: Back
Window 2 (Safari #115807):
- Position: (723, 220)
- Size: 574 × 491 [original width, original height]
- Role: LEADER
- Z-Order: Front
Key Design Decisions
Why Followers Are Smaller
- Visual clarity: Even with lag, followers won't peek out
- Click protection: User can't accidentally click on a follower
- Depth perception: Smaller size reinforces the stacking metaphor
Position Management Strategy
- Store original frames: Each window remembers its original size
- Leader uses original size: When becoming leader, restore original dimensions
- Followers use calculated size: Based on current leader's frame
Z-Order Management
- Leader always on top: Use focus/raise actions
- Followers always behind: Explicitly send to back
- Order within followers: Doesn't matter as long as all are behind leader
Performance Considerations
- Drag detection: Only poll during active drags (not constantly)
- Batch updates: Move all followers in one operation if possible
- Minimize resizing: Only resize when changing roles, not during drags
Current Implementation Issues
- Auto-leadership on add: Currently makes new windows leaders immediately
- Complex frame calculations:
calculateLeaderFrametries to reverse the follower calculation - Missing z-order management: No explicit "send to back" for followers
- No stored original frames: Can't properly restore original window sizes
Proposed Fixes
- Remove auto-leadership: Keep new windows as followers
- Store original dimensions: Add
originalSizefield to WindowInfo - Add z-order methods: Implement proper window layering
- Simplify calculations: Use stored frames instead of complex reversals
Taskspace Deletion System
Overview
Taskspace deletion is a complex operation that involves multiple safety checks, git cleanup, and coordination between the Swift app and VSCode extension. This document describes the architectural design and key insights.
System Architecture
Dialog Confirmation Flow
The deletion system now implements proper dialog confirmation to ensure agents receive accurate feedback:
Previous Flow (Problematic):
- Agent requests deletion → Immediate "success" response → UI dialog shown
- User could cancel, but agent already thought deletion succeeded
New Flow (Fixed):
- Agent requests deletion → No immediate response → UI dialog shown
- User confirms → Actual deletion → Success response to agent
- User cancels → Error response to agent ("Taskspace deletion was cancelled by user")
Key Implementation: The MessageHandlingResult::pending case allows the IPC system to defer responses until user interaction completes.
Safety-First Design
The deletion system prioritizes preventing data loss through a multi-layered safety approach:
- Fresh Branch Analysis: Computes git status when the deletion dialog opens (not when cached)
- Risk-Based Warnings: Shows specific warnings for different types of uncommitted work
- Smart Defaults: Auto-configures branch deletion toggle based on detected risks
- Graceful Fallbacks: Continues deletion even if git operations fail
Key Insight: Branch information must be computed fresh when the dialog appears, not when the app loads, because users may make commits between app startup and deletion attempts.
Cross-Process Coordination
The system coordinates between multiple processes:
- Swift App: Manages deletion workflow and safety checks
- VSCode Extension: Receives deletion broadcasts and closes windows gracefully
- Git Commands: Handle worktree and branch cleanup operations
Planned Enhancement: Broadcast taskspace_will_delete messages before file removal to allow VSCode windows to close gracefully, preventing "file not found" errors.
Git Worktree Integration
Architectural Constraints
The system works within git worktree constraints:
- Bare Repository: All git operations must run from the main repository directory
- Worktree Paths: Include repository name (e.g.,
task-UUID/reponame/) - Shared Metadata: Multiple worktrees share one
.gitdirectory
Critical Design Decision: All git commands execute from project.directoryPath (bare repo) rather than individual worktree directories, because worktrees only contain symlinks to the main git metadata.
Directory Structure
project/
├── .git/ # Bare repository (command execution context)
├── task-UUID1/
│ └── reponame/ # Git worktree (target for removal)
└── task-UUID2/
└── reponame/ # Another worktree
Design Principles
- Safety First: Always warn about potential data loss before proceeding
- Accurate Agent Feedback: Only respond to agents after user makes actual decision
- Fresh Data: Compute branch info when needed, not when cached
- Clear Communication: Provide specific warnings for different risk types
- Graceful Degradation: Continue deletion even when git operations fail
- User Control: Let users choose branch deletion behavior based on clear information
IPC Message Flow
Deferred Response Pattern
The delete_taskspace IPC message uses a deferred response pattern:
- Request Received:
handleDeleteTaskspacestores the message ID and returns.pending - No Immediate Response: IPC manager doesn't send response yet
- Dialog Interaction: User confirms or cancels in UI
- Deferred Response: Appropriate success/error response sent based on user choice
This ensures the MCP server and agent receive accurate information about whether the deletion actually occurred.
Complexity Drivers
Why This System is Complex
- Git Worktree Management: Multiple worktrees sharing one repository with complex path relationships
- Safety vs Convenience: Balance between preventing data loss and smooth user experience
- Timing Dependencies: Fresh computation requirements vs performance considerations
- Cross-Process Coordination: Swift app + VSCode extension + git subprocess coordination
- Error Recovery: Graceful fallbacks when git operations fail due to various reasons
Key Architectural Insights
- Fresh computation of branch info prevents stale warnings that could mislead users
- Correct path resolution is critical - git commands must target actual worktree paths
- Separate warning types improve user understanding of different risks
- Execution context matters - git commands must run from bare repository directory
Testing Strategy
Critical Test Scenarios
- Clean State: No commits, no changes → Should show "safe to delete"
- Unmerged Work: Commits not in main → Should warn with commit count
- Uncommitted Work: Modified files → Should warn about uncommitted changes
- Mixed State: Both unmerged and uncommitted → Should show both warnings
- Git Operations: Verify worktree and branch removal work without errors
- Window Coordination: VSCode windows should close gracefully during deletion
Edge Cases to Consider
- Detached HEAD: How does branch detection behave?
- Merge Conflicts: What happens with unresolved conflicts in worktree?
- Permission Issues: How does system handle git command failures?
- Concurrent Access: What if multiple processes access same worktree?
- Network Issues: How does remote branch checking handle connectivity problems?
Implementation References
Key Methods (see code comments for implementation details):
ProjectManager.getTaskspaceBranchInfo()- Branch safety analysisProjectManager.deleteTaskspace()- Main deletion workflowDeleteTaskspaceDialog- UI warning logic and user interaction
Critical Path Resolution (see deleteTaskspace() comments):
- Worktree path calculation and git command targeting
- Execution context setup for git operations
Safety Checking (see getTaskspaceBranchInfo() comments):
- Git command details and error handling
- Fresh computation timing and rationale
Persistent Agent Sessions
Enabling background, persistent AI agents that survive terminal disconnection
Overview
The Agent Process Manager enables persistent, asynchronous AI agents by wrapping CLI tools (Q CLI, Claude Code) in tmux sessions. This allows agents to:
- Run in the background independently of terminal sessions
- Persist across user disconnections
- Be attached/detached at will
- Continue work asynchronously
Architecture
graph TB
User[User Terminal] -->|attach/detach| TmuxSession[tmux Session]
AgentManager[Agent Manager] -->|spawn/kill| TmuxSession
TmuxSession -->|runs| AgentCLI[Agent CLI Tool]
AgentCLI -->|q chat --resume| MCPServer[MCP Server]
MCPServer -->|IPC| Daemon[Symposium Daemon]
AgentManager -->|persists| SessionFile[~/.symposium/agent-sessions.json]
style TmuxSession fill:#e1f5fe
style AgentManager fill:#f3e5f5
style SessionFile fill:#e8f5e8
Usage
Spawn Agent Session
symposium-mcp agent spawn --uuid my-agent-1 --workdir /path/to/project q chat --resume
List Active Sessions
symposium-mcp agent list
# Output:
# Active agent sessions:
# my-agent-1 - Running (symposium-agent-my-agent-1)
Attach to Session
symposium-mcp agent attach my-agent-1
# Output: To attach to agent session my-agent-1, run:
# tmux attach-session -t symposium-agent-my-agent-1
# Then run the command:
tmux attach-session -t symposium-agent-my-agent-1
Kill Session
symposium-mcp agent kill my-agent-1
Implementation Details
Session Management
- tmux Sessions: Each agent runs in a dedicated tmux session named
symposium-agent-{uuid} - Metadata Storage: Session info persisted in
~/.symposium/agent-sessions.json - Auto-Sync: On startup, syncs with actual tmux sessions to handle crashes/restarts
- Status Tracking: Monitors session state (Starting, Running, Crashed, Stopped)
Agent Lifecycle
- Spawn: Creates tmux session with agent command in specified working directory
- Monitor: Tracks session status and syncs with tmux reality
- Attach: Provides tmux attach command for user connection
- Detach: User can disconnect without killing agent (standard tmux behavior)
- Kill: Terminates tmux session and cleans up metadata
Session Persistence
#![allow(unused)] fn main() { #[derive(Debug, Clone, Serialize, Deserialize)] pub struct AgentSession { pub uuid: String, pub tmux_session_name: String, pub agent_command: Vec<String>, pub working_directory: PathBuf, pub status: AgentStatus, pub created_at: SystemTime, pub last_attached: Option<SystemTime>, } }
Integration with Existing System
Current Flow (Synchronous)
VSCode Extension → Terminal → Agent CLI (foreground) → Dies with terminal
New Flow (Persistent)
VSCode Extension → Agent Manager → tmux Session → Agent CLI (background)
↑
User Terminal ────────────────────────┘ (attach/detach)
Conversation Persistence
- CLI Tool Responsibility: Q CLI and Claude Code handle conversation history per directory
- Directory-Based:
q chat --resumeresumes last conversation in working directory - No Additional State: Agent Manager doesn't duplicate conversation storage
Future Enhancements
Custom Pty Manager
Consider replacing tmux with custom Rust implementation using:
Benefits:
- Eliminate tmux dependency
- More control over session lifecycle
- Custom attach/detach protocols
- Better integration with Symposium
Conversation Identification
Enhance CLI tools to support named conversations:
q chat --list-conversations
q chat --resume conversation-id-123
Multi-Connection Support
Allow multiple users/terminals to connect to same agent session simultaneously.
Background Task Queue
Enable agents to work on tasks asynchronously while disconnected:
symposium-mcp agent queue my-agent-1 "Implement authentication system"
Error Handling
Session Recovery
- Crashed Sessions: Detected during sync, marked as
Crashedstatus - Orphaned Metadata: Sessions without tmux counterpart are cleaned up
- Startup Sync: Reconciles stored sessions with actual tmux sessions
tmux Availability
- Missing tmux: Commands fail gracefully with clear error messages
- Permission Issues: Standard tmux error handling applies
Testing
Manual Testing
# Test basic lifecycle
symposium-mcp agent spawn --uuid test-1 --workdir /tmp sleep 30
symposium-mcp agent list
symposium-mcp agent attach test-1
# (attach and verify session works)
symposium-mcp agent kill test-1
# Test with real agent
symposium-mcp agent spawn --uuid q-test --workdir /path/to/project q chat
symposium-mcp agent attach q-test
# (interact with Q CLI, detach with Ctrl-B D, reattach)
Integration Testing
- Verify agent CLI tools work correctly in tmux sessions
- Test MCP server connectivity from tmux-spawned agents
- Validate conversation persistence across attach/detach cycles
Security Considerations
Session Isolation
- Each agent runs in separate tmux session
- Working directory isolation per agent
- No shared state between agent sessions
File Permissions
- Session metadata stored in user home directory
- Standard tmux socket permissions apply
- No elevation of privileges required
Related Documentation
- Implementation Overview - Current synchronous agent system
- Taskspace Bootup Flow - How agents are currently launched
- Agent Manager Source - Implementation details
Agent Manager
Symposium supports two execution models for AI agents:
Synchronous Agents (Current Default)
- Execution: Agents run in VSCode integrated terminals as foreground processes
- Lifecycle: Agent dies when terminal closes or VSCode exits
- State: Conversation history managed by CLI tools per directory
- Use Case: Interactive development sessions with direct terminal access
Persistent Agents (New Capability)
- Execution: Agents run in background tmux sessions managed by Agent Manager
- Lifecycle: Agents persist across terminal disconnections and VSCode restarts
- State: Session metadata in
~/.symposium/agent-sessions.json, conversation history still managed by CLI tools - Use Case: Long-running tasks, asynchronous work, multi-session collaboration
Agent Manager Commands
# Spawn persistent agent session
symposium-mcp agent spawn --uuid my-agent --workdir /path/to/project q chat
# List active sessions
symposium-mcp agent list
# Attach to running session
symposium-mcp agent attach my-agent
# Kill session
symposium-mcp agent kill my-agent
Persistent Agent Architecture
graph TB
User[User Terminal] -->|attach/detach| TmuxSession[tmux Session]
AgentManager[Agent Manager] -->|spawn/kill| TmuxSession
TmuxSession -->|runs| AgentCLI[Agent CLI Tool]
AgentCLI -->|q chat --resume| MCPServer[MCP Server]
MCPServer -->|IPC| Daemon[Symposium Daemon]
AgentManager -->|persists| SessionFile[~/.symposium/agent-sessions.json]
style TmuxSession fill:#e1f5fe
style AgentManager fill:#f3e5f5
style SessionFile fill:#e8f5e8
Research reports
This section contains research reports that we have commissioned that give details of how things work. Sometimes its useful to point your agent at these reports so they can get the details into context.
Continue.dev GUI Integration Guide
Document Version: 1.0
Based on Continue.dev: v1.4.46 (October 2025) / main branch
Repository: https://github.com/continuedev/continue
Last Updated: October 9, 2025
Document Overview
This guide explains how to reuse Continue.dev's production-quality chat GUI in your own VS Code extension by implementing their message-passing protocol architecture. Continue.dev was specifically designed with a modular architecture where the GUI communicates with the backend purely through well-defined message protocols, making the GUI genuinely reusable across different implementations.
Key insight: Continue.dev already supports both VS Code and JetBrains IDEs using the same GUI codebase, proving the architecture's portability.
Architecture Overview
Continue.dev uses a three-layer message-passing architecture:
┌─────────────────────────────────────┐
│ GUI (React + Redux) │
│ - Runs in VS Code webview │
│ - Built separately with Vite │
│ - Located in gui/ folder │
└──────────────┬──────────────────────┘
│ Webview postMessage
┌──────────────┴──────────────────────┐
│ Extension (VS Code API) │
│ - Hosts webview │
│ - Routes messages │
│ - Implements IDE interface │
└──────────────┬──────────────────────┘
│ JSON-RPC / stdio
┌──────────────┴──────────────────────┐
│ Core (Business Logic) │
│ - LLM interactions │
│ - Configuration │
│ - Context providers │
└─────────────────────────────────────┘
For your use case, you'd replace Core with your ACP agent:
┌─────────────────────────────────────┐
│ Continue GUI (unchanged) │
└──────────────┬──────────────────────┘
│ Continue protocols
┌──────────────┴──────────────────────┐
│ YOUR Extension (adapter layer) │
└──────────────┬──────────────────────┘
│ Your interface
┌──────────────┴──────────────────────┐
│ YOUR Core → ACP Agent │
└─────────────────────────────────────┘
Architecture Source Files
- Codebase layout documentation:
continuedev/vscode - Messaging architecture: Defined in
core/protocol/ - GUI components:
gui/src/components/ - VS Code extension entry:
extensions/vscode/src/activation/activate.ts
Protocol Messages
The protocols are defined in core/protocol/ and consist of four message types:
1. ToWebviewFromIdeProtocol (Extension → GUI)
Messages the extension sends to the GUI.
Key protocol file: core/protocol/ide.ts
// Common messages you'll need to handle:
{
messageType: "configUpdate",
data: { config: SerializedContinueConfig }
}
{
messageType: "configError",
data: { message: string }
}
{
messageType: "newSessionWithPrompt",
data: { prompt: string }
}
{
messageType: "addContextItem",
data: {
item: ContextItem,
historyIndex: number
}
}
// Streaming LLM response
{
messageType: "llmStreamChunk",
data: {
chunk: ChatMessage,
index: number
}
}
References:
- Protocol definitions:
core/protocol/index.ts - IDE message types:
core/protocol/ide.ts
2. ToIdeFromWebviewProtocol (GUI → Extension)
Messages the GUI sends that you need to handle.
Key protocol file: core/protocol/webview.ts
// User sends a message
{
messageType: "userInput",
data: {
input: string,
contextItems: ContextItem[]
}
}
// User selects a context provider (@file, @code, etc.)
{
messageType: "loadContextProvider",
data: {
name: string,
params: any
}
}
// User stops generation
{
messageType: "stopGeneration",
data: {}
}
// User changes model
{
messageType: "setModel",
data: {
model: string
}
}
// Request for file contents
{
messageType: "readRangeInFile",
data: {
filepath: string,
range: { start: number, end: number }
}
}
References:
- Webview protocol:
core/protocol/webview.ts - Message handling in VS Code:
extensions/vscode/src/VsCodeExtension.ts
3. ToCoreFromWebviewProtocol (GUI → Core)
These go through the extension first, so you'd intercept and handle them:
{
messageType: "sendChatMessage",
data: {
message: string,
modelTitle: string
}
}
References:
- Core protocol:
core/protocol/core.ts
4. ToWebviewFromCoreProtocol (Core → GUI)
Messages you'd send from your ACP adapter back to the GUI:
// Stream LLM tokens
{
messageType: "llmStream",
data: {
content: string,
done: boolean,
index: number
}
}
// Tool/function call
{
messageType: "toolCall",
data: {
toolCallId: string,
name: string,
arguments: object
}
}
Key Data Types
ContextItem
Type definition: core/index.d.ts
interface ContextItem {
name: string;
description: string;
content: string;
id?: string;
editing?: boolean;
editable?: boolean;
}
ChatMessage
Type definition: core/index.d.ts
interface ChatMessage {
role: "user" | "assistant" | "system";
content: string | Array<{ type: string; text?: string; imageUrl?: string }>;
toolCalls?: ToolCall[];
}
SerializedContinueConfig
Type definition: core/index.d.ts
interface SerializedContinueConfig {
models: Array<{
title: string;
provider: string;
model: string;
apiKey?: string;
}>;
contextProviders?: ContextProviderWithParams[];
slashCommands?: SlashCommandDescription[];
// ... many other optional fields
}
Full type definitions: core/index.d.ts
Webview Integration - The Nitty Gritty
Step 1: Create Webview Panel
Reference implementation: extensions/vscode/src/ContinueGUIWebviewViewProvider.ts
import * as vscode from 'vscode';
import * as path from 'path';
export class ContinueGuiProvider implements vscode.WebviewViewProvider {
private _view?: vscode.WebviewView;
constructor(
private readonly _extensionUri: vscode.Uri,
private readonly _guiDistPath: string
) {}
public resolveWebviewView(
webviewView: vscode.WebviewView,
context: vscode.WebviewViewResolveContext,
_token: vscode.CancellationToken
) {
this._view = webviewView;
webviewView.webview.options = {
enableScripts: true,
localResourceRoots: [
vscode.Uri.file(this._guiDistPath)
]
};
// Load the Continue GUI HTML
webviewView.webview.html = this._getHtmlForWebview(webviewView.webview);
// Set up message handlers
this._setupMessageHandlers(webviewView.webview);
}
private _getHtmlForWebview(webview: vscode.Webview): string {
// Path to the Continue GUI dist folder
const scriptUri = webview.asWebviewUri(
vscode.Uri.file(path.join(this._guiDistPath, 'assets', 'index.js'))
);
const styleUri = webview.asWebviewUri(
vscode.Uri.file(path.join(this._guiDistPath, 'assets', 'index.css'))
);
// Generate nonce for CSP
const nonce = getNonce();
return `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="Content-Security-Policy" content="
default-src 'none';
style-src ${webview.cspSource} 'unsafe-inline';
script-src 'nonce-${nonce}';
connect-src https:;
">
<link href="${styleUri}" rel="stylesheet">
<title>Continue</title>
</head>
<body>
<div id="root"></div>
<script nonce="${nonce}">
window.windowId = "${getNonce()}";
window.serverUrl = "http://localhost:3000"; // Your server if needed
window.vscMediaUrl = "${webview.asWebviewUri(vscode.Uri.file(this._guiDistPath))}";
window.ide = "vscode";
</script>
<script nonce="${nonce}" src="${scriptUri}"></script>
</body>
</html>`;
}
private _setupMessageHandlers(webview: vscode.Webview) {
// Listen for messages FROM the webview
webview.onDidReceiveMessage(
async (message) => {
await this.handleWebviewMessage(message);
}
);
}
// Send messages TO the webview
public postMessage(message: any): void {
this._view?.webview.postMessage(message);
}
private async handleWebviewMessage(message: any): Promise<void> {
const { messageType, data } = message;
switch (messageType) {
case "userInput":
await this.handleUserInput(data);
break;
case "loadContextProvider":
await this.handleContextProvider(data);
break;
case "stopGeneration":
this.stopCurrentGeneration();
break;
case "setModel":
this.setModel(data.model);
break;
// ... handle other message types
}
}
private async handleUserInput(data: any): Promise<void> {
const { input, contextItems } = data;
// This is where you'd call YOUR ACP agent
// Send the prompt to your ACP agent and stream responses back
// Example: Send to ACP agent
const response = await this.yourAcpClient.sendMessage({
prompt: input,
context: contextItems
});
// Stream tokens back to GUI
for await (const chunk of response) {
this.postMessage({
messageType: "llmStreamChunk",
data: {
chunk: { role: "assistant", content: chunk },
index: 0
}
});
}
// Signal completion
this.postMessage({
messageType: "llmStreamChunk",
data: {
chunk: { role: "assistant", content: "" },
index: 0,
done: true
}
});
}
}
function getNonce(): string {
let text = '';
const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for (let i = 0; i < 32; i++) {
text += possible.charAt(Math.floor(Math.random() * possible.length));
}
return text;
}
Reference files:
- Webview provider:
extensions/vscode/src/ContinueGUIWebviewViewProvider.ts - HTML generation utilities:
extensions/vscode/src/util/getExtensionUri.ts
Step 2: Register in activate()
Reference implementation: extensions/vscode/src/activation/activate.ts
export function activate(context: vscode.ExtensionContext) {
// Path to Continue's GUI build output
const guiDistPath = path.join(context.extensionPath, 'continue-gui', 'dist');
const provider = new ContinueGuiProvider(
context.extensionUri,
guiDistPath
);
// Register the webview provider
context.subscriptions.push(
vscode.window.registerWebviewViewProvider(
'continue.continueGUIView',
provider,
{
webviewOptions: {
retainContextWhenHidden: true
}
}
)
);
}
Step 3: package.json Configuration
Reference: extensions/vscode/package.json
{
"contributes": {
"viewsContainers": {
"activitybar": [
{
"id": "continue",
"title": "Continue",
"icon": "media/icon.svg"
}
]
},
"views": {
"continue": [
{
"type": "webview",
"id": "continue.continueGUIView",
"name": "Continue"
}
]
}
}
}
Building the Continue GUI
Continue's GUI is built separately with Vite.
Build configuration: gui/vite.config.ts
# In the Continue repo
cd gui
npm install
npm run build
# Output goes to gui/dist
# Copy this to your extension:
cp -r gui/dist your-extension/continue-gui/dist
Build scripts: gui/package.json
Protocol Adapter Pattern
The key abstraction is creating a thin adapter:
class AcpToContinueAdapter {
constructor(
private acpClient: YourAcpClient,
private webviewProvider: ContinueGuiProvider
) {}
async sendChatMessage(message: string, contextItems: ContextItem[]) {
// Translate Continue format → ACP format
const acpRequest = {
prompt: message,
context: contextItems.map(item => ({
content: item.content,
name: item.name
}))
};
// Send to ACP agent
const stream = await this.acpClient.streamChat(acpRequest);
// Translate ACP responses → Continue format
for await (const chunk of stream) {
this.webviewProvider.postMessage({
messageType: "llmStreamChunk",
data: {
chunk: { role: "assistant", content: chunk.content },
index: 0
}
});
}
}
}
Source Code Reference Map
Core Architecture
- Protocol definitions:
core/protocol/ - Type definitions:
core/index.d.ts - Core system overview: DeepWiki - Core System
GUI Layer
- Main GUI components:
gui/src/components/ - Chat component:
gui/src/pages/gui/Chat.tsx - Layout component:
gui/src/components/Layout.tsx - Input component:
gui/src/components/mainInput/ContinueInputBox.tsx - GUI system overview: DeepWiki - GUI System
VS Code Extension
- Extension entry:
extensions/vscode/src/activation/activate.ts - Webview provider:
extensions/vscode/src/ContinueGUIWebviewViewProvider.ts - VS Code extension class:
extensions/vscode/src/VsCodeExtension.ts - Package manifest:
extensions/vscode/package.json - VS Code extension overview: DeepWiki - VS Code Extension
Communication Flow
- Message passing:
core/protocol/messenger/ - Communication flow overview: DeepWiki - Communication Flow
Context Providers
- Context providers:
core/context/providers/ - Context provider docs: Continue Docs - Context Providers
No Helper Libraries (Yet)
Continue doesn't currently provide a standalone library for hosting their GUI - you need to:
- Clone their repo and build the GUI
- Copy the GUI dist to your extension
- Implement the protocol handlers yourself
- Host the webview using VS Code's standard webview API
The good news: their protocol is well-defined and message-passing makes this clean.
Summary
What you get:
- Production-quality React chat UI
- Message history
- Context provider system (@file, @code, etc.)
- Model selection UI
- Stop generation button
- Streaming support
What you build:
- ~300-400 lines of adapter code
- Protocol message handlers
- Integration with your ACP client
- Webview hosting boilerplate
Reusability: Very high - the GUI is truly decoupled via message passing, just as advertised!
Additional Resources
- Main Repository: https://github.com/continuedev/continue
- Documentation: https://docs.continue.dev
- Discord Community: https://discord.gg/vapESyrFmJ
- Contributing Guide:
CONTRIBUTING.md - Architecture Deep Dive: DeepWiki Documentation
Version History
| Version | Date | Changes |
|---|---|---|
| 1.0 | Oct 9, 2025 | Initial document based on Continue.dev v1.4.46 |
License: This guide is provided for educational purposes. Continue.dev is licensed under Apache 2.0. See their LICENSE file for details.
Testing VSCode Extensions: Official Framework and Best Practices
Official VSCode testing setup
Microsoft provides an official testing framework for VSCode extensions through @vscode/test-cli and @vscode/test-electron. This is the recommended approach for extension testing.
Core philosophy
The official framework launches a real VSCode instance (Extension Development Host) with your extension loaded, allowing you to test against actual VSCode APIs rather than mocks. This ensures your tests match production behavior.
Installation and setup
Install dependencies
npm install --save-dev @vscode/test-cli @vscode/test-electron mocha @types/mocha
Configure test runner
Create .vscode-test.js (or .vscode-test.mjs) in your project root:
// .vscode-test.js
const { defineConfig } = require('@vscode/test-cli');
module.exports = defineConfig({
files: 'out/test/**/*.test.js',
version: 'stable', // or 'insiders', '1.75.0', etc.
workspaceFolder: './test-fixtures',
mocha: {
ui: 'tdd',
timeout: 20000,
color: true
},
// Use env vars to control test behavior
env: {
MOCK_CLIENT_MODE: 'true'
}
});
Project structure
your-extension/
├── src/
│ ├── extension.ts
│ ├── clientConnection.ts
│ └── test/
│ ├── runTest.ts # Optional: custom test runner
│ └── suite/
│ ├── index.ts # Mocha configuration
│ ├── connection.test.ts
│ ├── panels.test.ts
│ ├── comments.test.ts
│ └── chat.test.ts
├── test-fixtures/ # Test workspace files
│ ├── sample.js
│ └── .vscode/
│ └── settings.json
├── .vscode-test.js
└── package.json
Package.json scripts
{
"scripts": {
"compile": "tsc -p ./",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile",
"test": "vscode-test"
}
}
Test suite configuration
Mocha setup (required)
// src/test/suite/index.ts
import * as path from 'path';
import * as Mocha from 'mocha';
import { glob } from 'glob';
export function run(): Promise<void> {
// Create the mocha test
const mocha = new Mocha({
ui: 'tdd',
color: true,
timeout: 10000
});
const testsRoot = path.resolve(__dirname, '..');
return new Promise((resolve, reject) => {
glob('**/**.test.js', { cwd: testsRoot })
.then((files) => {
// Add files to the test suite
files.forEach(f => mocha.addFile(path.resolve(testsRoot, f)));
try {
// Run the mocha test
mocha.run(failures => {
if (failures > 0) {
reject(new Error(`${failures} tests failed.`));
} else {
resolve();
}
});
} catch (err) {
console.error(err);
reject(err);
}
})
.catch((err) => {
reject(err);
});
});
}
Extension activation in tests
Your extension will be automatically activated when tests run. You can configure this behavior:
// src/extension.ts
import * as vscode from 'vscode';
export function activate(context: vscode.ExtensionContext) {
// Check if running in test mode
const isTestMode = process.env.MOCK_CLIENT_MODE === 'true';
// Configure based on environment
const clientConfig = isTestMode
? { useMockClient: true }
: { useMockClient: false };
// Initialize your extension
const connection = new ClientConnection(clientConfig);
context.subscriptions.push(connection);
}
Writing integration tests
Test structure with TDD style
// src/test/suite/connection.test.ts
import * as assert from 'assert';
import * as vscode from 'vscode';
suite('Client Connection Tests', () => {
setup(() => {
// Runs before each test
});
teardown(() => {
// Runs after each test
});
test('Should establish connection', async () => {
// Your test code
assert.ok(true);
});
test('Should handle incoming messages', async () => {
// Your test code
});
});
Testing with BDD style (alternative)
// .vscode-test.js
module.exports = defineConfig({
mocha: {
ui: 'bdd', // Change to BDD
}
});
// src/test/suite/connection.test.ts
import * as assert from 'assert';
import * as vscode from 'vscode';
describe('Client Connection Tests', () => {
beforeEach(() => {
// Setup
});
afterEach(() => {
// Teardown
});
it('should establish connection', async () => {
// Your test code
});
});
Testing panel/webview interactions
What you CAN test
// src/test/suite/panels.test.ts
import * as assert from 'assert';
import * as vscode from 'vscode';
suite('Panel Display Tests', () => {
teardown(() => {
// Always clean up
vscode.commands.executeCommand('workbench.action.closeAllEditors');
});
test('Should create webview panel', async () => {
// Trigger panel creation
await vscode.commands.executeCommand('yourExtension.showPanel');
// You CAN verify:
// - That panel was created (track in your extension)
// - Panel properties (title, viewType)
// - That webview exists
// You can expose panel state for testing:
const panels = getExtensionPanels(); // You implement this
assert.strictEqual(panels.size, 1);
const panel = panels.get('main');
assert.ok(panel);
assert.strictEqual(panel.title, 'Expected Title');
assert.ok(panel.visible);
});
test('Should communicate with webview via postMessage', async () => {
await vscode.commands.executeCommand('yourExtension.showPanel');
const panel = getExtensionPanels().get('main');
// Listen for messages from webview
const messagePromise = new Promise((resolve) => {
const disposable = panel.webview.onDidReceiveMessage((msg) => {
disposable.dispose();
resolve(msg);
});
});
// Send message to webview
panel.webview.postMessage({ command: 'test' });
// Wait for response
const response = await messagePromise;
assert.strictEqual(response.status, 'ok');
});
test('Should update panel on subsequent messages', async () => {
// Trigger initial panel
await vscode.commands.executeCommand('yourExtension.showPanel', {
content: 'Initial'
});
await sleep(100);
// Update panel
await vscode.commands.executeCommand('yourExtension.showPanel', {
content: 'Updated'
});
await sleep(100);
// Verify state updated (requires tracking in extension)
const panelState = getExtensionPanelState('main');
assert.strictEqual(panelState.content, 'Updated');
});
});
function sleep(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
What you CANNOT test directly
Critical limitations:
- Cannot access webview DOM: The webview content is sandboxed and inaccessible from extension tests
- Cannot verify visual appearance: No way to check CSS, layout, or rendered HTML
- Cannot simulate user clicks inside webview: Webview interactions are isolated
Workaround: Use message passing between extension and webview to query state:
// In your webview HTML/JS
window.addEventListener('message', event => {
const message = event.data;
if (message.command === 'getState') {
// Report current state back to extension
vscode.postMessage({
command: 'stateResponse',
data: {
content: getCurrentContent(),
buttonEnabled: isButtonEnabled(),
// ... other state
}
});
}
});
// In your test
test('Should render correct content in webview', async () => {
const panel = getPanel();
const statePromise = new Promise((resolve) => {
panel.webview.onDidReceiveMessage((msg) => {
if (msg.command === 'stateResponse') {
resolve(msg.data);
}
});
});
// Request state from webview
panel.webview.postMessage({ command: 'getState' });
const state = await statePromise;
assert.strictEqual(state.content, 'Expected content');
});
Testing code comments and decorations
What you CAN test
// src/test/suite/comments.test.ts
import * as assert from 'assert';
import * as vscode from 'vscode';
suite('Code Comment Tests', () => {
let testDoc: vscode.TextDocument;
let editor: vscode.TextEditor;
setup(async () => {
// Create test document
testDoc = await vscode.workspace.openTextDocument({
content: 'function test() {\n return 42;\n}\n',
language: 'javascript'
});
editor = await vscode.window.showTextDocument(testDoc);
});
teardown(async () => {
await vscode.commands.executeCommand('workbench.action.closeAllEditors');
});
test('Should insert comment into document', async () => {
// Simulate client message triggering comment insertion
await vscode.commands.executeCommand('yourExtension.addComment', {
fileUri: testDoc.uri.toString(),
line: 1,
text: '// Generated comment'
});
await sleep(100);
// You CAN verify: Document text was modified
const line = testDoc.lineAt(1).text;
assert.ok(line.includes('// Generated comment'));
});
test('Should insert multiple comments', async () => {
const fileUri = testDoc.uri.toString();
await vscode.commands.executeCommand('yourExtension.addComment', {
fileUri, line: 0, text: '// First'
});
await vscode.commands.executeCommand('yourExtension.addComment', {
fileUri, line: 2, text: '// Second'
});
await sleep(200);
assert.ok(testDoc.lineAt(0).text.includes('// First'));
assert.ok(testDoc.lineAt(2).text.includes('// Second'));
});
test('Should handle comment at end of file', async () => {
const lastLine = testDoc.lineCount - 1;
await vscode.commands.executeCommand('yourExtension.addComment', {
fileUri: testDoc.uri.toString(),
line: lastLine,
text: '// End comment'
});
await sleep(100);
const text = testDoc.lineAt(lastLine).text;
assert.ok(text.includes('// End comment'));
});
});
function sleep(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
What you CANNOT test directly
Critical limitation: VSCode provides no API to retrieve or inspect decorations.
When you call editor.setDecorations(decorationType, ranges), there is no corresponding method to get those decorations back.
// This does NOT work - no such API exists
const decorations = editor.getDecorations(); // ❌ No such method
const decorations = testDoc.getDecorations(); // ❌ No such method
Workarounds:
- Track decorations in your extension code:
// In your extension
class DecorationManager {
private static decorations = new Map<string, vscode.TextEditorDecorationType>();
static setDecoration(editor: vscode.TextEditor, type: string, ranges: vscode.Range[]) {
const decorationType = vscode.window.createTextEditorDecorationType({
backgroundColor: 'rgba(255, 200, 0, 0.3)'
});
editor.setDecorations(decorationType, ranges);
this.decorations.set(type, decorationType);
}
// Test-only method
static __testOnly_hasDecoration(type: string): boolean {
if (process.env.NODE_ENV !== 'test') {
throw new Error('Test-only method');
}
return this.decorations.has(type);
}
}
// In your test
test('Should apply decoration', async () => {
await vscode.commands.executeCommand('yourExtension.addComment', {
fileUri: testDoc.uri.toString(),
line: 0,
text: '// Comment'
});
await sleep(100);
// Can only verify decoration was set, not its appearance
assert.ok(DecorationManager.__testOnly_hasDecoration('comment'));
});
- Test decoration logic separately (unit test):
// Unit test the decoration creation logic
suite('Decoration Logic', () => {
test('Should create correct decoration ranges', () => {
const ranges = calculateDecorationRanges(/* params */);
assert.strictEqual(ranges.length, 2);
assert.strictEqual(ranges[0].start.line, 0);
assert.strictEqual(ranges[0].end.line, 0);
});
});
- Use E2E testing (see section below)
Testing chat interface
// src/test/suite/chat.test.ts
import * as assert from 'assert';
import * as vscode from 'vscode';
suite('Chat Interface Tests', () => {
test('Should send message through extension', async () => {
// Execute command that sends chat message
const result = await vscode.commands.executeCommand(
'yourExtension.sendChatMessage',
'Test message'
);
// If your command returns a promise with response:
assert.ok(result);
assert.strictEqual(result.status, 'sent');
});
test('Should handle chat response from client', async () => {
// This test assumes your mock client (Rust) responds via env var config
const responsePromise = new Promise((resolve) => {
// Register listener for chat response event
const disposable = vscode.workspace.onDidChangeConfiguration((e) => {
if (e.affectsConfiguration('yourExtension.lastChatResponse')) {
disposable.dispose();
resolve(vscode.workspace.getConfiguration('yourExtension').get('lastChatResponse'));
}
});
});
await vscode.commands.executeCommand(
'yourExtension.sendChatMessage',
'Hello'
);
const response = await responsePromise;
assert.ok(response);
});
test('Should display chat in UI', async () => {
// Open chat panel
await vscode.commands.executeCommand('yourExtension.showChat');
const panels = getExtensionPanels();
assert.ok(panels.has('chat'));
const chatPanel = panels.get('chat');
assert.strictEqual(chatPanel.title, 'Chat');
assert.ok(chatPanel.visible);
});
});
Design patterns for testability
1. Expose state for testing
Create a test-only API to access extension internals:
// src/extensionState.ts
export class ExtensionState {
private static panels = new Map<string, vscode.WebviewPanel>();
private static decorations = new Map<string, any>();
static registerPanel(id: string, panel: vscode.WebviewPanel) {
this.panels.set(id, panel);
}
static getPanel(id: string): vscode.WebviewPanel | undefined {
return this.panels.get(id);
}
// Test-only methods
static __testOnly_getAllPanels(): Map<string, vscode.WebviewPanel> {
if (process.env.NODE_ENV !== 'test') {
throw new Error('Test-only method');
}
return this.panels;
}
static __testOnly_clearState() {
if (process.env.NODE_ENV !== 'test') {
throw new Error('Test-only method');
}
this.panels.clear();
this.decorations.clear();
}
}
2. Use environment variables for test configuration
// src/extension.ts
export function activate(context: vscode.ExtensionContext) {
const config = {
mockMode: process.env.MOCK_CLIENT_MODE === 'true',
mockDelay: parseInt(process.env.MOCK_DELAY || '100'),
};
const connection = new ClientConnection(config);
// ...
}
3. Create test utilities
// src/test/suite/testUtils.ts
import * as vscode from 'vscode';
export async function createTestDocument(
content: string,
language: string = 'javascript'
): Promise<vscode.TextDocument> {
const doc = await vscode.workspace.openTextDocument({
content,
language
});
return doc;
}
export async function openTestEditor(doc: vscode.TextDocument): Promise<vscode.TextEditor> {
return await vscode.window.showTextDocument(doc);
}
export function sleep(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
export async function closeAllEditors(): Promise<void> {
await vscode.commands.executeCommand('workbench.action.closeAllEditors');
}
export async function waitForCondition(
condition: () => boolean,
timeout: number = 5000,
interval: number = 100
): Promise<void> {
const start = Date.now();
while (!condition()) {
if (Date.now() - start > timeout) {
throw new Error('Timeout waiting for condition');
}
await sleep(interval);
}
}
4. Always clean up in teardown
suite('My Tests', () => {
let disposables: vscode.Disposable[] = [];
teardown(async () => {
// Dispose all resources
disposables.forEach(d => d.dispose());
disposables = [];
// Close all editors
await vscode.commands.executeCommand('workbench.action.closeAllEditors');
// Clear extension state
ExtensionState.__testOnly_clearState();
});
test('Something', async () => {
const subscription = vscode.workspace.onDidChangeConfiguration(() => {});
disposables.push(subscription);
// ...
});
});
Advanced test runner (optional)
For more control, you can use a custom test runner instead of vscode-test:
// src/test/runTest.ts
import * as path from 'path';
import { runTests } from '@vscode/test-electron';
async function main() {
try {
const extensionDevelopmentPath = path.resolve(__dirname, '../../');
const extensionTestsPath = path.resolve(__dirname, './suite/index');
const testWorkspace = path.resolve(__dirname, '../../test-fixtures');
// Download and run VS Code tests
await runTests({
extensionDevelopmentPath,
extensionTestsPath,
launchArgs: [
testWorkspace,
'--disable-extensions', // Disable other extensions
'--disable-gpu' // Better for CI
],
extensionTestsEnv: {
MOCK_CLIENT_MODE: 'true',
NODE_ENV: 'test'
}
});
} catch (err) {
console.error('Failed to run tests');
console.error(err);
process.exit(1);
}
}
main();
Then update package.json:
{
"scripts": {
"test": "vscode-test",
"test:custom": "node ./out/test/runTest.js"
}
}
End-to-end testing with vscode-extension-tester
For scenarios where you must verify visual UI state, use vscode-extension-tester (built on Selenium):
npm install --save-dev vscode-extension-tester
This framework launches VSCode and automates the UI through Selenium WebDriver, allowing you to:
- Verify webview DOM content
- Check decoration appearance
- Simulate user clicks and interactions
- Verify notification content
Tradeoffs:
- Much slower than integration tests (30-60s per test vs 1-2s)
- More brittle (breaks with UI changes)
- Harder to debug
- Requires X server on Linux (xvfb)
Use sparingly for critical user workflows only:
// src/test/ui/panel.ui.test.ts
import { VSBrowser, WebView, By, until } from 'vscode-extension-tester';
describe('Panel UI Tests', () => {
let browser: VSBrowser;
before(async function() {
this.timeout(30000);
browser = VSBrowser.instance;
});
it('should display correct content in webview', async function() {
this.timeout(30000);
// Trigger panel via command palette
await browser.openResources();
const input = await browser.openCommandPrompt();
await input.setText('>Show My Panel');
await input.confirm();
await browser.driver.sleep(2000);
// Access webview
const webview = new WebView();
await webview.switchToFrame();
// Now you can verify DOM
const heading = await webview.findWebElement(By.css('h1'));
const text = await heading.getText();
assert.strictEqual(text, 'Expected Title');
const button = await webview.findWebElement(By.id('myButton'));
assert.ok(await button.isDisplayed());
await webview.switchBack();
});
});
Run E2E tests:
npx extest setup-and-run out/test/ui/*.test.js
CI/CD configuration
GitHub Actions
# .github/workflows/test.yml
name: Test Extension
on: [push, pull_request]
jobs:
test:
strategy:
matrix:
os: [ubuntu-latest, windows-latest, macos-latest]
runs-on: ${{ matrix.os }}
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '18'
- run: npm install
- run: npm run compile
# Linux requires xvfb for headless VSCode
- name: Run tests (Linux)
if: runner.os == 'Linux'
run: xvfb-run -a npm test
- name: Run tests (Windows/Mac)
if: runner.os != 'Linux'
run: npm test
Azure Pipelines
# azure-pipelines.yml
trigger:
- main
strategy:
matrix:
linux:
imageName: 'ubuntu-latest'
mac:
imageName: 'macos-latest'
windows:
imageName: 'windows-latest'
pool:
vmImage: $(imageName)
steps:
- task: NodeTool@0
inputs:
versionSpec: '18.x'
- script: npm install
displayName: 'Install dependencies'
- script: npm run compile
displayName: 'Compile'
- bash: |
/usr/bin/Xvfb :99 -screen 0 1024x768x24 > /dev/null 2>&1 &
echo ">>> Started xvfb"
displayName: 'Start xvfb'
condition: eq(variables['Agent.OS'], 'Linux')
- script: npm test
displayName: 'Run tests'
env:
DISPLAY: ':99.0'
Testing best practices summary
Do's
✅ Use official @vscode/test-cli framework - It's the recommended approach
✅ Test against real VSCode APIs - More reliable than mocking
✅ Use environment variables for test configuration
✅ Expose test-only state access methods in your extension
✅ Clean up resources in teardown hooks
✅ Wait for async operations with appropriate delays
✅ Test message passing between extension and webviews
✅ Track key state in your extension for verification
✅ Use integration tests for 80%+ of your testing
✅ Test on multiple platforms in CI/CD
Don'ts
❌ Don't try to access webview DOM in integration tests (use E2E instead)
❌ Don't try to retrieve decorations programmatically (track in extension)
❌ Don't forget to close editors in teardown
❌ Don't make tests too slow (save E2E for critical paths only)
❌ Don't test implementation details - test observable behavior
❌ Don't skip CI testing on Windows/Mac if you support them
❌ Don't use sleeps excessively - prefer event-driven waits when possible
Recommended test distribution
- 70% Integration tests (fast, reliable, test API interactions)
- 20% Unit tests (fastest, test pure logic)
- 10% E2E tests (slow but comprehensive, test critical UI workflows)
This approach gives you fast, maintainable tests that run against a real VSCode instance while avoiding the limitations of trying to verify visual UI state programmatically.
Language Server Protocol (LSP) - Comprehensive Overview
Executive Summary
The Language Server Protocol (LSP) defines the protocol used between an editor or IDE and a language server that provides language features like auto complete, go to definition, find all references etc. The goal of the Language Server Index Format (LSIF, pronounced like "else if") is to support rich code navigation in development tools or a Web UI without needing a local copy of the source code.
The idea behind the Language Server Protocol (LSP) is to standardize the protocol for how tools and servers communicate, so a single Language Server can be re-used in multiple development tools, and tools can support languages with minimal effort.
Key Benefits:
- Reduces M×N complexity to M+N (one server per language instead of one implementation per editor per language)
- Enables language providers to focus on a single high-quality implementation
- Allows editors to support multiple languages with minimal effort
- Standardized JSON-RPC based communication
Table of Contents
- Architecture & Core Concepts
- Base Protocol
- Message Types
- Capabilities System
- Lifecycle Management
- Document Synchronization
- Language Features
- Workspace Features
- Window Features
- Implementation Considerations
- Version History
Architecture & Core Concepts
Problem Statement
Prior to the design and implementation of the Language Server Protocol for the development of Visual Studio Code, most language services were generally tied to a given IDE or other editor. In the absence of the Language Server Protocol, language services are typically implemented by using a tool-specific extension API.
This created a classic M×N complexity problem where:
- M = Number of editors/IDEs
- N = Number of programming languages
- Total implementations needed = M × N
LSP Solution
The idea behind a Language Server is to provide the language-specific smarts inside a server that can communicate with development tooling over a protocol that enables inter-process communication.
Architecture Components:
- Language Client: The editor/IDE that requests language services
- Language Server: A separate process providing language intelligence
- LSP: The standardized communication protocol between them
Communication Model:
- JSON-RPC 2.0 based messaging
- A language server runs as a separate process and development tools communicate with the server using the language protocol over JSON-RPC.
- Bi-directional communication (client ↔ server)
- Support for synchronous requests and asynchronous notifications
Supported Languages & Environments
LSP is not restricted to programming languages. It can be used for any kind of text-based language, like specifications or domain-specific languages (DSL).
Transport Options:
- stdio (standard input/output)
- Named pipes (Windows) / Unix domain sockets
- TCP sockets
- Node.js IPC
This comprehensive overview provides the foundation for understanding and implementing Language Server Protocol solutions. Each section can be expanded into detailed implementation guides as needed.
Base Protocol
Message Structure
The base protocol consists of a header and a content part (comparable to HTTP). The header and content part are separated by a '\r\n'.
Header Format
Content-Length: <number>\r\n
Content-Type: application/vscode-jsonrpc; charset=utf-8\r\n
\r\n
Required Headers:
Content-Length: Length of content in bytes (mandatory)Content-Type: MIME type (optional, defaults toapplication/vscode-jsonrpc; charset=utf-8)
Content Format
Contains the actual content of the message. The content part of a message uses JSON-RPC to describe requests, responses and notifications.
Example Message:
Content-Length: 126\r\n
\r\n
{
"jsonrpc": "2.0",
"id": 1,
"method": "textDocument/completion",
"params": {
"textDocument": { "uri": "file:///path/to/file.js" },
"position": { "line": 5, "character": 10 }
}
}
JSON-RPC Structure
Base Message
interface Message {
jsonrpc: string; // Always "2.0"
}
Request Message
interface RequestMessage extends Message {
id: integer | string;
method: string;
params?: array | object;
}
Response Message
interface ResponseMessage extends Message {
id: integer | string | null;
result?: any;
error?: ResponseError;
}
Notification Message
interface NotificationMessage extends Message {
method: string;
params?: array | object;
}
Error Handling
Standard Error Codes:
-32700: Parse error-32600: Invalid Request-32601: Method not found-32602: Invalid params-32603: Internal error
LSP-Specific Error Codes:
-32803: RequestFailed-32802: ServerCancelled-32801: ContentModified-32800: RequestCancelled
Language Features
Language Features provide the actual smarts in the language server protocol. They are usually executed on a [text document, position] tuple. The main language feature categories are: code comprehension features like Hover or Goto Definition. coding features like diagnostics, code complete or code actions.
Navigation Features
Go to Definition
textDocument/definition: TextDocumentPositionParams → Location | Location[] | LocationLink[] | null
Go to Declaration
textDocument/declaration: TextDocumentPositionParams → Location | Location[] | LocationLink[] | null
Go to Type Definition
textDocument/typeDefinition: TextDocumentPositionParams → Location | Location[] | LocationLink[] | null
Go to Implementation
textDocument/implementation: TextDocumentPositionParams → Location | Location[] | LocationLink[] | null
Find References
textDocument/references: ReferenceParams → Location[] | null
interface ReferenceParams extends TextDocumentPositionParams {
context: { includeDeclaration: boolean; }
}
Information Features
Hover
textDocument/hover: TextDocumentPositionParams → Hover | null
interface Hover {
contents: MarkedString | MarkedString[] | MarkupContent;
range?: Range;
}
Signature Help
textDocument/signatureHelp: SignatureHelpParams → SignatureHelp | null
interface SignatureHelp {
signatures: SignatureInformation[];
activeSignature?: uinteger;
activeParameter?: uinteger;
}
Document Symbols
textDocument/documentSymbol: DocumentSymbolParams → DocumentSymbol[] | SymbolInformation[] | null
Workspace Symbols
workspace/symbol: WorkspaceSymbolParams → SymbolInformation[] | WorkspaceSymbol[] | null
Code Intelligence Features
Code Completion
textDocument/completion: CompletionParams → CompletionItem[] | CompletionList | null
interface CompletionList {
isIncomplete: boolean;
items: CompletionItem[];
}
interface CompletionItem {
label: string;
kind?: CompletionItemKind;
detail?: string;
documentation?: string | MarkupContent;
sortText?: string;
filterText?: string;
insertText?: string;
textEdit?: TextEdit;
additionalTextEdits?: TextEdit[];
}
Completion Triggers:
- User invoked (Ctrl+Space)
- Trigger characters (
.,->, etc.) - Incomplete completion re-trigger
Code Actions
textDocument/codeAction: CodeActionParams → (Command | CodeAction)[] | null
interface CodeAction {
title: string;
kind?: CodeActionKind;
diagnostics?: Diagnostic[];
isPreferred?: boolean;
disabled?: { reason: string; };
edit?: WorkspaceEdit;
command?: Command;
}
Code Action Kinds:
quickfix- Fix problemsrefactor- Refactoring operationssource- Source code actions (organize imports, etc.)
Code Lens
textDocument/codeLens: CodeLensParams → CodeLens[] | null
interface CodeLens {
range: Range;
command?: Command;
data?: any; // For resolve support
}
Formatting Features
Document Formatting
textDocument/formatting: DocumentFormattingParams → TextEdit[] | null
Range Formatting
textDocument/rangeFormatting: DocumentRangeFormattingParams → TextEdit[] | null
On-Type Formatting
textDocument/onTypeFormatting: DocumentOnTypeFormattingParams → TextEdit[] | null
Semantic Features
Semantic Tokens
Since version 3.16.0. The request is sent from the client to the server to resolve semantic tokens for a given file. Semantic tokens are used to add additional color information to a file that depends on language specific symbol information.
textDocument/semanticTokens/full: SemanticTokensParams → SemanticTokens | null
textDocument/semanticTokens/range: SemanticTokensRangeParams → SemanticTokens | null
textDocument/semanticTokens/full/delta: SemanticTokensDeltaParams → SemanticTokens | SemanticTokensDelta | null
Token Encoding:
- 5 integers per token:
[deltaLine, deltaStart, length, tokenType, tokenModifiers] - Relative positioning for efficiency
- Bit flags for modifiers
Inlay Hints
textDocument/inlayHint: InlayHintParams → InlayHint[] | null
interface InlayHint {
position: Position;
label: string | InlayHintLabelPart[];
kind?: InlayHintKind; // Type | Parameter
tooltip?: string | MarkupContent;
paddingLeft?: boolean;
paddingRight?: boolean;
}
Diagnostics
Push Model (Traditional)
textDocument/publishDiagnostics: PublishDiagnosticsParams
interface PublishDiagnosticsParams {
uri: DocumentUri;
version?: integer;
diagnostics: Diagnostic[];
}
Pull Model (Since 3.17)
textDocument/diagnostic: DocumentDiagnosticParams → DocumentDiagnosticReport
workspace/diagnostic: WorkspaceDiagnosticParams → WorkspaceDiagnosticReport
Diagnostic Structure:
interface Diagnostic {
range: Range;
severity?: DiagnosticSeverity; // Error | Warning | Information | Hint
code?: integer | string;
source?: string; // e.g., "typescript"
message: string;
tags?: DiagnosticTag[]; // Unnecessary | Deprecated
relatedInformation?: DiagnosticRelatedInformation[];
}
Implementation Guide
Performance Guidelines
Message Ordering: Responses to requests should be sent in roughly the same order as the requests appear on the server or client side.
State Management:
- Servers should handle partial/incomplete requests gracefully
- Use
ContentModifiederror for outdated results - Implement proper cancellation support
Resource Management:
- Language servers run in separate processes
- Avoid memory leaks in long-running servers
- Implement proper cleanup on shutdown
Error Handling
Client Responsibilities:
- Restart crashed servers (with exponential backoff)
- Handle
ContentModifiederrors gracefully - Validate server responses
Server Responsibilities:
- Return appropriate error codes
- Handle malformed/outdated requests
- Monitor client process health
Transport Considerations
Command Line Arguments:
language-server --stdio # Use stdio
language-server --pipe=<n> # Use named pipe/socket
language-server --socket --port=<port> # Use TCP socket
language-server --node-ipc # Use Node.js IPC
language-server --clientProcessId=<pid> # Monitor client process
Testing Strategies
Unit Testing:
- Mock LSP message exchange
- Test individual feature implementations
- Validate message serialization/deserialization
Integration Testing:
- End-to-end editor integration
- Multi-document scenarios
- Error condition handling
Performance Testing:
- Large file handling
- Memory usage patterns
- Response time benchmarks
Advanced Topics
Custom Extensions
Experimental Capabilities:
interface ClientCapabilities {
experimental?: {
customFeature?: boolean;
vendorSpecificExtension?: any;
};
}
Custom Methods:
- Use vendor prefixes:
mycompany/customFeature - Document custom protocol extensions
- Ensure graceful degradation
Security Considerations
Process Isolation:
- Language servers run in separate processes
- Limit file system access appropriately
- Validate all input from untrusted sources
Content Validation:
- Sanitize file paths and URIs
- Validate document versions
- Implement proper input validation
Multi-Language Support
Language Identification:
interface TextDocumentItem {
uri: DocumentUri;
languageId: string; // "typescript", "python", etc.
version: integer;
text: string;
}
Document Selectors:
type DocumentSelector = DocumentFilter[];
interface DocumentFilter {
language?: string; // "typescript"
scheme?: string; // "file", "untitled"
pattern?: string; // "**/*.{ts,js}"
}
Message Reference
Message Types
Request/Response Pattern
Client-to-Server Requests:
initialize- Server initializationtextDocument/hover- Get hover informationtextDocument/completion- Get code completionstextDocument/definition- Go to definition
Server-to-Client Requests:
client/registerCapability- Register new capabilitiesworkspace/configuration- Get configuration settingswindow/showMessageRequest- Show message with actions
Notification Pattern
Client-to-Server Notifications:
initialized- Initialization completetextDocument/didOpen- Document openedtextDocument/didChange- Document changedtextDocument/didSave- Document savedtextDocument/didClose- Document closed
Server-to-Client Notifications:
textDocument/publishDiagnostics- Send diagnosticswindow/showMessage- Display messagetelemetry/event- Send telemetry data
Special Messages
Dollar Prefixed Messages: Notifications and requests whose methods start with '$/' are messages which are protocol implementation dependent and might not be implementable in all clients or servers.
Examples:
$/cancelRequest- Cancel ongoing request$/progress- Progress reporting$/setTrace- Set trace level
Capabilities System
Not every language server can support all features defined by the protocol. LSP therefore provides 'capabilities'. A capability groups a set of language features.
Capability Exchange
During Initialization:
- Client announces capabilities in
initializerequest - Server announces capabilities in
initializeresponse - Both sides adapt behavior based on announced capabilities
Client Capabilities Structure
interface ClientCapabilities {
workspace?: WorkspaceClientCapabilities;
textDocument?: TextDocumentClientCapabilities;
window?: WindowClientCapabilities;
general?: GeneralClientCapabilities;
experimental?: any;
}
Key Client Capabilities:
textDocument.hover.dynamicRegistration- Support dynamic hover registrationtextDocument.completion.contextSupport- Support completion contextworkspace.workspaceFolders- Multi-root workspace supportwindow.workDoneProgress- Progress reporting support
Server Capabilities Structure
interface ServerCapabilities {
textDocumentSync?: TextDocumentSyncKind | TextDocumentSyncOptions;
completionProvider?: CompletionOptions;
hoverProvider?: boolean | HoverOptions;
definitionProvider?: boolean | DefinitionOptions;
referencesProvider?: boolean | ReferenceOptions;
documentSymbolProvider?: boolean | DocumentSymbolOptions;
workspaceSymbolProvider?: boolean | WorkspaceSymbolOptions;
codeActionProvider?: boolean | CodeActionOptions;
// ... many more
}
Dynamic Registration
Servers can register/unregister capabilities after initialization:
// Register new capability
client/registerCapability: {
registrations: [{
id: "uuid",
method: "textDocument/willSaveWaitUntil",
registerOptions: { documentSelector: [{ language: "javascript" }] }
}]
}
// Unregister capability
client/unregisterCapability: {
unregisterations: [{ id: "uuid", method: "textDocument/willSaveWaitUntil" }]
}
Lifecycle Management
Initialization Sequence
-
Client → Server:
initializerequestinterface InitializeParams { processId: integer | null; clientInfo?: { name: string; version?: string; }; rootUri: DocumentUri | null; initializationOptions?: any; capabilities: ClientCapabilities; workspaceFolders?: WorkspaceFolder[] | null; } -
Server → Client:
initializeresponseinterface InitializeResult { capabilities: ServerCapabilities; serverInfo?: { name: string; version?: string; }; } -
Client → Server:
initializednotification- Signals completion of initialization
- Server can now send requests to client
Shutdown Sequence
-
Client → Server:
shutdownrequest- Server must not accept new requests (except
exit) - Server should finish processing ongoing requests
- Server must not accept new requests (except
-
Client → Server:
exitnotification- Server should exit immediately
- Exit code: 0 if shutdown was called, 1 otherwise
Process Monitoring
Client Process Monitoring:
- Server can monitor client process via
processIdfrom initialize - Server should exit if client process dies
Server Crash Handling:
- Client should restart crashed servers
- Implement exponential backoff to prevent restart loops
Document Synchronization
Client support for textDocument/didOpen, textDocument/didChange and textDocument/didClose notifications is mandatory in the protocol and clients can not opt out supporting them.
Text Document Sync Modes
enum TextDocumentSyncKind {
None = 0, // No synchronization
Full = 1, // Full document sync on every change
Incremental = 2 // Incremental sync (deltas only)
}
Document Lifecycle
Document Open
textDocument/didOpen: {
textDocument: {
uri: "file:///path/to/file.js",
languageId: "javascript",
version: 1,
text: "console.log('hello');"
}
}
Document Change
textDocument/didChange: {
textDocument: { uri: "file:///path/to/file.js", version: 2 },
contentChanges: [{
range: { start: { line: 0, character: 12 }, end: { line: 0, character: 17 } },
text: "world"
}]
}
Change Event Types:
- Full text: Replace entire document
- Incremental: Specify range and replacement text
Document Save
// Optional: Before save
textDocument/willSave: {
textDocument: { uri: "file:///path/to/file.js" },
reason: TextDocumentSaveReason.Manual
}
// Optional: Before save with text edits
textDocument/willSaveWaitUntil → TextEdit[]
// After save
textDocument/didSave: {
textDocument: { uri: "file:///path/to/file.js" },
text?: "optional full text"
}
Document Close
textDocument/didClose: {
textDocument: { uri: "file:///path/to/file.js" }
}
Position Encoding
Prior to 3.17 the offsets were always based on a UTF-16 string representation. Since 3.17 clients and servers can agree on a different string encoding representation (e.g. UTF-8).
Supported Encodings:
utf-16(default, mandatory)utf-8utf-32
Position Structure:
interface Position {
line: uinteger; // Zero-based line number
character: uinteger; // Zero-based character offset
}
interface Range {
start: Position;
end: Position;
}
Workspace Features
Multi-Root Workspaces
workspace/workspaceFolders → WorkspaceFolder[] | null
interface WorkspaceFolder {
uri: URI;
name: string;
}
// Notification when folders change
workspace/didChangeWorkspaceFolders: DidChangeWorkspaceFoldersParams
Configuration Management
// Server requests configuration from client
workspace/configuration: ConfigurationParams → any[]
interface ConfigurationItem {
scopeUri?: URI; // Scope (file/folder) for the setting
section?: string; // Setting name (e.g., "typescript.preferences")
}
// Client notifies server of configuration changes
workspace/didChangeConfiguration: DidChangeConfigurationParams
File Operations
File Watching
workspace/didChangeWatchedFiles: DidChangeWatchedFilesParams
interface FileEvent {
uri: DocumentUri;
type: FileChangeType; // Created | Changed | Deleted
}
File System Operations
// Before operations (can return WorkspaceEdit)
workspace/willCreateFiles: CreateFilesParams → WorkspaceEdit | null
workspace/willRenameFiles: RenameFilesParams → WorkspaceEdit | null
workspace/willDeleteFiles: DeleteFilesParams → WorkspaceEdit | null
// After operations (notifications)
workspace/didCreateFiles: CreateFilesParams
workspace/didRenameFiles: RenameFilesParams
workspace/didDeleteFiles: DeleteFilesParams
Command Execution
workspace/executeCommand: ExecuteCommandParams → any
interface ExecuteCommandParams {
command: string; // Command identifier
arguments?: any[]; // Command arguments
}
// Server applies edits to workspace
workspace/applyEdit: ApplyWorkspaceEditParams → ApplyWorkspaceEditResult
Window Features
Message Display
Show Message (Notification)
window/showMessage: ShowMessageParams
interface ShowMessageParams {
type: MessageType; // Error | Warning | Info | Log | Debug
message: string;
}
Show Message Request
window/showMessageRequest: ShowMessageRequestParams → MessageActionItem | null
interface ShowMessageRequestParams {
type: MessageType;
message: string;
actions?: MessageActionItem[]; // Buttons to show
}
Show Document
window/showDocument: ShowDocumentParams → ShowDocumentResult
interface ShowDocumentParams {
uri: URI;
external?: boolean; // Open in external program
takeFocus?: boolean; // Focus the document
selection?: Range; // Select range in document
}
Progress Reporting
Work Done Progress
// Server creates progress token
window/workDoneProgress/create: WorkDoneProgressCreateParams → void
// Report progress using $/progress
$/progress: ProgressParams<WorkDoneProgressBegin | WorkDoneProgressReport | WorkDoneProgressEnd>
// Client can cancel progress
window/workDoneProgress/cancel: WorkDoneProgressCancelParams
Progress Reporting Pattern
// Begin
{ kind: "begin", title: "Indexing", cancellable: true, percentage: 0 }
// Report
{ kind: "report", message: "Processing file.ts", percentage: 25 }
// End
{ kind: "end", message: "Indexing complete" }
Logging & Telemetry
window/logMessage: LogMessageParams // Development logs
telemetry/event: any // Usage analytics
Version History
LSP 3.17 (Current)
Major new feature are: type hierarchy, inline values, inlay hints, notebook document support and a meta model that describes the 3.17 LSP version.
Key Features:
- Type hierarchy support
- Inline value provider
- Inlay hints
- Notebook document synchronization
- Diagnostic pull model
- Position encoding negotiation
LSP 3.16
Key Features:
- Semantic tokens
- Call hierarchy
- Moniker support
- File operation events
- Linked editing ranges
- Code action resolve
LSP 3.15
Key Features:
- Progress reporting
- Selection ranges
- Signature help context
LSP 3.0
Breaking Changes:
- Client capabilities system
- Dynamic registration
- Workspace folders
- Document link support